
这是很早之前写的一个笔记,仅供大家参考,如果你想学习和使用doris,也可以直接和我联系。
Drois介绍
Doris是基于 MPP 的交互式 SQL 数据仓库,主要用于解决报表和多维分析问题
名词解释
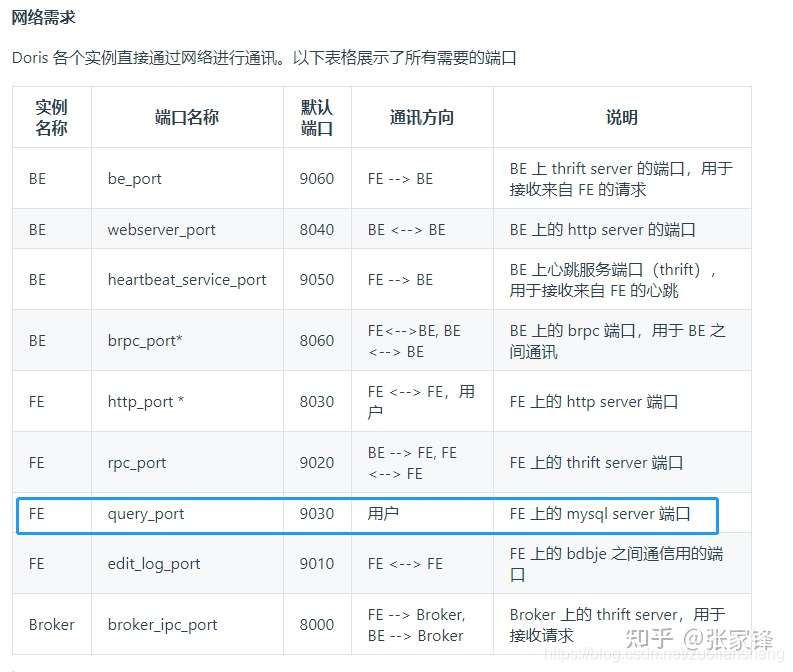
- Frontend(FE):Doris 系统的元数据和调度节点。在导入流程中主要负责导入任务的调度工作。
- Backend(BE):Doris 系统的计算和存储节点。在导入流程中主要负责数据写入及存储。
- Spark ETL:在导入流程中主要负责数据的 ETL 工作,包括全局字典构建(BITMAP类型)、分区、排序、聚合等。
- Broker:Broker 为一个独立的无状态进程。封装了文件系统接口,提供 Doris 读取远端存储系统中文件的能力
环境安装部署
docker安装
yum install net-tools -y
ifconfig
更新yum仓库
yum update
安装插件
yum install -y yum-utils device-mapper-persistent-data lvm2
添加yum源阿里云
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
查看可以安装的docker版本
yum list docker-ce --showduplicates | sort -r
安装docker
yum install docker-ce-18.03.1.ce
修改存储目录
vi /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd --graph /home/docker
https://blog.csdn.net/u014069688/article/details/100532774
安装ETCD
网络环境: docker需要开启防火墙
systemctl restart firewalld.service && systemctl enable firewalld.service
master 安装: 安装 etcd 及配置 [root@master ~]# yum install -y etcd [root@master ~]# systemctl restart etcd
配置开机启动: [root@master ~]# systemctl enable etcd
配置etcd [root@master ~]# vim /etc/etcd/etcd.conf
修改
ETCD_LISTEN_CLIENT_URLS=”http://localhost:2379” ETCD_ADVERTISE_CLIENT_URLS=”http://localhost:2379”
为
ETCD_LISTEN_CLIENT_URLS=”http://192.168.10.11:2379,http://127.0.0.1:2379”
ETCD_ADVERTISE_CLIENT_URLS=”http://192.168.10.11:2379”
etcd 设置网段(这个网段将会分配给 flannel0 网卡): [root@master ~]# etcdctl mk /atomic.io/network/config ‘{“Network”:”172.20.0.0/16”,”SubnetMin”:”172.20.1.0”,”SubnetMax”:”172.20.254.0”}’
[root@master ~]# etcdctl get /http://atomic.io/network/config
[root@master ~]# etcdctl get /
/http://atomic.io/network/config #此文件对应/etc/sysconfig/flannel中的FLANNEL_ETCD_PREFIX
[root@master ~]# systemctl restart etcd #创建网段后,需要重启etcd,否则后面不能启动flannel
安装flannel
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。但在默认的Docker配置中,
每个节点上的Docker服务会分别负责所在节点容器的IP分配。这样导致的一个问题是,不同节点上容器可能获得相同的内外IP地址。并使这些容器之间能够之间通过IP地址相互找到,也就是相
互ping通。
Flannel的设计目的就是为集群中的所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得"同属一个内网"且"不重复的"IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。
Flannel实质上是一种"覆盖网络(overlay network)",即表示运行在一个网上的网(应用层网络),并不依靠ip地址来传递消息,而是采用一种映射机制,把ip地址和identifiers做映射来资源定位。也就
是将TCP数据包装在另一种网络包里面进行路由转发和通信,目前已经支持UDP、VxLAN、AWS VPC和GCE路由等数据转发方式。
原理是每个主机配置一个ip段和子网个数。例如,可以配置一个覆盖网络使用 10.100.0.0/16段,每个主机/24个子网。因此主机a可以接受10.100.5.0/24,主机B可以接受10.100.18.0/24的包。flannel使用etcd来维护分配的子网到实际的ip地址之间的映射。对于数据路径,flannel 使用udp来封装ip数据报,转发到远程主机。选择UDP作为转发协议是因为他能穿透防火墙。例如,AWS Classic无法转发IPoIP or GRE 网络包,是因为它的安全组仅仅支持TCP/UDP/ICMP。
flannel 使用etcd存储配置数据和子网分配信息。flannel 启动之后,后台进程首先检索配置和正在使用的子网列表,然后选择一个可用的子网,然后尝试去注册它。
etcd也存储这个每个主机对应的ip。flannel 使用etcd的watch机制监视/coreos.com/network/subnets下面所有元素的变化信息,并且根据他来维护一个路由表。为了提高性能,flannel优化了Universal TAP/TUN设备,对TUN和UDP之间的ip分片做了代理。
默认的节点间数据通信方式是UDP转发.在Flannel的GitHub页面有如下的一张原理图:
1)数据从源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel0虚拟网卡,这是个P2P的虚拟网卡,flanneld服务监听在网卡的另外一端。
2)Flannel通过Etcd服务维护了一张节点间的路由表,在稍后的配置部分我们会介绍其中的内容。
3)源主机的flanneld服务将原本的数据内容UDP封装后根据自己的路由表投递给目的节点的flanneld服务,数据到达以后被解包,然后直接进入目的节点的flannel0虚拟网卡,
然后被转发到目的主机的docker0虚拟网卡,最后就像本机容器通信一下的有docker0路由到达目标容器。
这样整个数据包的传递就完成了,这里需要解释三个问题:
1)UDP封装是怎么回事?
在UDP的数据内容部分其实是另一个ICMP(也就是ping命令)的数据包。原始数据是在起始节点的Flannel服务上进行UDP封装的,投递到目的节点后就被另一端的Flannel服务
还原成了原始的数据包,两边的Docker服务都感觉不到这个过程的存在。
2)为什么每个节点上的Docker会使用不同的IP地址段?
这个事情看起来很诡异,但真相十分简单。其实只是单纯的因为Flannel通过Etcd分配了每个节点可用的IP地址段后,偷偷的修改了Docker的启动参数。
在运行了Flannel服务的节点上可以查看到Docker服务进程运行参数(ps aux|grep docker|grep "bip"),例如“--bip=182.48.25.1/24”这个参数,它限制了所在节
点容器获得的IP范围。这个IP范围是由Flannel自动分配的,由Flannel通过保存在Etcd服务中的记录确保它们不会重复。
3)为什么在发送节点上的数据会从docker0路由到flannel0虚拟网卡,在目的节点会从flannel0路由到docker0虚拟网卡?
例如现在有一个数据包要从IP为172.17.18.2的容器发到IP为172.17.46.2的容器。根据数据发送节点的路由表,它只与172.17.0.0/16匹配这条记录匹配,因此数据从docker0
出来以后就被投递到了flannel0。同理在目标节点,由于投递的地址是一个容器,因此目的地址一定会落在docker0对于的172.17.46.0/24这个记录上,自然的被投递到了docker0网卡。
Flannel环境部署记录
1)机器环境(centos7系统)
182.48.115.233 部署etcd,flannel,docker 主机名:node-1 主控端(通过etcd)
182.48.115.235 部署flannel,docker 主机名:node-2 被控端
2)node-1(182.48.115.233)机器操作
设置主机名及绑定hosts
[root@node-1 ~]# hostnamectl --static set-hostname node-1
[root@node-1 ~]# vim /etc/hosts
182.48.115.233 node-1
182.48.115.233 etcd
182.48.115.235 node-2
关闭防火墙,如果开启防火墙,则最好打开2379和4001端口
[root@node-1 ~]# systemctl disable firewalld.service
[root@node-1 ~]# systemctl stop firewalld.service
先安装docker环境
[root@node-1 ~]# yum install -y docker
安装etcd
k8s运行依赖etcd,需要先部署etcd,下面采用yum方式安装:
[root@node-1 ~]# yum install etcd -y
yum安装的etcd默认配置文件在/etc/etcd/etcd.conf,编辑配置文件:
[root@node-1 ~]# cp /etc/etcd/etcd.conf /etc/etcd/etcd.conf.bak
[root@node-1 ~]# cat /etc/etcd/etcd.conf
#[member]
ETCD_NAME=master #节点名称
ETCD_DATA_DIR="/var/lib/etcd/default.etcd" #数据存放位置
#ETCD_WAL_DIR=""
#ETCD_SNAPSHOT_COUNT="10000"
#ETCD_HEARTBEAT_INTERVAL="100"
#ETCD_ELECTION_TIMEOUT="1000"
#ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379,http://0.0.0.0:4001" #监听客户端地址
#ETCD_MAX_SNAPSHOTS="5"
#ETCD_MAX_WALS="5"
#ETCD_CORS=""
#
#[cluster]
#ETCD_INITIAL_ADVERTISE_PEER_URLS="http://localhost:2380"
# if you use different ETCD_NAME (e.g. test), set ETCD_INITIAL_CLUSTER value for this name, i.e. "test=http://..."
#ETCD_INITIAL_CLUSTER="default=http://localhost:2380"
#ETCD_INITIAL_CLUSTER_STATE="new"
#ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_ADVERTISE_CLIENT_URLS="http://etcd:2379,http://etcd:4001" #通知客户端地址
#ETCD_DISCOVERY=""
#ETCD_DISCOVERY_SRV=""
#ETCD_DISCOVERY_FALLBACK="proxy"
#ETCD_DISCOVERY_PROXY=""
启动etcd并验证状态
[root@node-1 ~]# systemctl start etcd
[root@node-1 ~]# ps -ef|grep etcd
etcd 28145 1 1 14:38 ? 00:00:00 /usr/bin/etcd --name=master --data-dir=/var/lib/etcd/default.etcd --listen-client-urls=http://0.0.0.0:2379,http://0.0.0.0:4001
root 28185 24819 0 14:38 pts/1 00:00:00 grep --color=auto etcd
[root@node-1 ~]# lsof -i:2379
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
etcd 28145 etcd 6u IPv6 1283822 0t0 TCP *:2379 (LISTEN)
etcd 28145 etcd 18u IPv6 1284133 0t0 TCP localhost:53203->localhost:2379 (ESTABLISHED)
........
[root@node-1 ~]# etcdctl set testdir/testkey0 0
0
[root@node-1 ~]# etcdctl get testdir/testkey0
0
[root@node-1 ~]# etcdctl -C http://etcd:4001 cluster-health
member 8e9e05c52164694d is healthy: got healthy result from http://etcd:2379
cluster is healthy
[root@node-1 ~]# etcdctl -C http://etcd:2379 cluster-health
member 8e9e05c52164694d is healthy: got healthy result from http://etcd:2379
cluster is healthy
安装覆盖网络Flannel
[root@node-1 ~]# yum install flannel
配置Flannel
[root@node-1 ~]# cp /etc/sysconfig/flanneld /etc/sysconfig/flanneld.bak
[root@node-1 ~]# vim /etc/sysconfig/flanneld
# Flanneld configuration options
# etcd url location. Point this to the server where etcd runs
FLANNEL_ETCD_ENDPOINTS="http://etcd:2379"
# etcd config key. This is the configuration key that flannel queries
# For address range assignment
FLANNEL_ETCD_PREFIX="/atomic.io/network"
# Any additional options that you want to pass
#FLANNEL_OPTIONS=""
配置etcd中关于flannel的key(这个只在安装了etcd的机器上操作)
Flannel使用Etcd进行配置,来保证多个Flannel实例之间的配置一致性,所以需要在etcd上进行如下配置('/atomic.io/network/config'这个key与上文/etc/sysconfig/flannel中的配置项FLANNEL_ETCD_PREFIX是相对应的,错误的话启动就会出错):
[root@node-1 ~]# etcdctl mk /atomic.io/network/config '{ "Network": "182.48.0.0/16" }'
{ "Network": "182.48.0.0/16" }
温馨提示:上面flannel设置的ip网段可以任意设定,随便设定一个网段都可以。容器的ip就是根据这个网段进行自动分配的,ip分配后,容器一般是可以对外联网的(网桥模式,只要宿主机能上网就可以)
启动Flannel
[root@node-1 ~]# systemctl enable flanneld.service
[root@node-1 ~]# systemctl start flanneld.service
[root@node-1 ~]# ps -ef|grep flannel
root 9305 9085 0 09:12 pts/2 00:00:00 grep --color=auto flannel
root 28876 1 0 May15 ? 00:00:07 /usr/bin/flanneld -etcd-endpoints=http://etcd:2379 -etcd-prefix=/atomic.io/network
启动Flannel后,一定要记得重启docker,这样Flannel配置分配的ip才能生效,即docker0虚拟网卡的ip会变成上面flannel设定的ip段
[root@node-1 ~]# systemctl restart docker
3)node-2(182.48.115.235)机器操作
设置主机名及绑定hosts
[root@node-2 ~]# hostnamectl --static set-hostname node-2
[root@node-2 ~]# vim /etc/hosts
182.48.115.233 node-1
182.48.115.233 etcd
182.48.115.235 node-2
关闭防火墙,如果开启防火墙,则最好打开2379和4001端口
[root@node-2 ~]# systemctl disable firewalld.service
[root@node-2 ~]# systemctl stop firewalld.service
先安装docker环境
[root@node-2 ~]# yum install -y docker
安装覆盖网络Flannel
[root@node-2 ~]# yum install flannel
配置Flannel
[root@node-2 ~]# cp /etc/sysconfig/flanneld /etc/sysconfig/flanneld.bak
[root@node-2 ~]# vim /etc/sysconfig/flanneld
# Flanneld configuration options
# etcd url location. Point this to the server where etcd runs
FLANNEL_ETCD_ENDPOINTS="http://etcd:2379"
# etcd config key. This is the configuration key that flannel queries
# For address range assignment
FLANNEL_ETCD_PREFIX="/atomic.io/network"
# Any additional options that you want to pass
#FLANNEL_OPTIONS=""
启动Flannel
[root@node-2 ~]# systemctl enable flanneld.service
[root@node-2 ~]# systemctl start flanneld.service
[root@node-2 ~]# ps -ef|grep flannel
root 3841 9649 0 09:11 pts/0 00:00:00 grep --color=auto flannel
root 28995 1 0 May15 ? 00:00:07 /usr/bin/flanneld -etcd-endpoints=http://etcd:2379 -etcd-prefix=/atomic.io/network
启动Flannel后,一定要记得重启docker,这样Flannel配置分配的ip才能生效,即docker0虚拟网卡的ip会变成上面flannel设定的ip段
[root@node-2 ~]# systemctl restart docker
先要放开两台主机访问的防火墙:
[root@master ~]# iptables -I INPUT -s 192.168.10.0/24 -j ACCEPT
[root@slave01 ~]# iptables -I INPUT -s 192.168.10.0/24 -j ACCEPT
4)创建容器,验证跨主机容器之间的网络联通性
首先在node-1(182.48.115.233)上容器容器,如下,登陆容器发现已经按照上面flannel配置的分配了一个ip段(每个宿主机都会分配一个182.48.0.0/16的网段)
[root@node-1 ~]# docker run -ti -d --name=node-1.test docker.io/nginx /bin/bash
5e403bf93857fa28b42c9e2abaa5781be4e2bc118ba0c25cb6355b9793dd107e
[root@node-1 ~]# docker exec -ti node-1.test /bin/bash
root@5e403bf93857:/# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2953: eth0@if2954: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue state UP group default
link/ether 02:42:b6:30:19:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 182.48.25.4/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:b6ff:fe30:1904/64 scope link
valid_lft forever preferred_lft forever
接着在node-2(182.48.115.233)上容器容器
[root@node-2 ~]# docker exec -ti node-2.test /bin/bash
root@052a6a2a4a19:/# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
10: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue state UP group default
link/ether 02:42:b6:30:43:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 182.48.67.3/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:b6ff:fe30:4303/64 scope link
valid_lft forever preferred_lft forever
root@052a6a2a4a19:/# ping 182.48.25.4
PING 182.48.25.4 (182.48.25.4): 56 data bytes
64 bytes from 182.48.25.4: icmp_seq=0 ttl=60 time=2.463 ms
64 bytes from 182.48.25.4: icmp_seq=1 ttl=60 time=1.211 ms
.......
root@052a6a2a4a19:/# ping www.baidu.com
PING www.a.shifen.com (14.215.177.37): 56 data bytes
64 bytes from 14.215.177.37: icmp_seq=0 ttl=51 time=39.404 ms
64 bytes from 14.215.177.37: icmp_seq=1 ttl=51 time=39.437 ms
.......
发现,在两个宿主机的容器内,互相ping对方容器的ip,是可以ping通的!也可以直接连接外网(桥接模式)
查看两台宿主机的网卡信息,发现docker0虚拟网卡的ip(相当于容器的网关)也已经变成了flannel配置的ip段,并且多了flannel0的虚拟网卡信息
[root@node-1 ~]# ifconfig
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1472
inet 182.48.25.1 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::42:31ff:fe0f:cf0f prefixlen 64 scopeid 0x20<link>
ether 02:42:31:0f:cf:0f txqueuelen 0 (Ethernet)
RX packets 48 bytes 2952 (2.8 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 31 bytes 2286 (2.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 182.48.115.233 netmask 255.255.255.224 broadcast 182.48.115.255
inet6 fe80::5054:ff:fe34:782 prefixlen 64 scopeid 0x20<link>
ether 52:54:00:34:07:82 txqueuelen 1000 (Ethernet)
RX packets 10759798 bytes 2286314897 (2.1 GiB)
RX errors 0 dropped 40 overruns 0 frame 0
TX packets 21978639 bytes 1889026515 (1.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
flannel0: flags=4305<UP,POINTOPOINT,RUNNING,NOARP,MULTICAST> mtu 1472
inet 182.48.25.0 netmask 255.255.0.0 destination 182.48.25.0
unspec 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00 txqueuelen 500 (UNSPEC)
RX packets 12 bytes 1008 (1008.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 12 bytes 1008 (1008.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
通过下面命令,可以查看到本机的容器的ip所在的范围
[root@node-1 ~]# ps aux|grep docker|grep "bip"
root 2080 0.0 1.4 796864 28168 ? Ssl May15 0:18 /usr/bin/dockerd-current --add-runtime docker-runc=/usr/libexec/docker/docker-runc-current --default-runtime=docker-runc --exec-opt native.cgroupdriver=systemd --userland-proxy-path=/usr/libexec/docker/docker-proxy-current --insecure-registry registry:5000 --bip=182.48.25.1/24 --ip-masq=true --mtu=1472
这里面的“--bip=182.48.25.1/24”这个参数,它限制了所在节点容器获得的IP范围。
这个IP范围是由Flannel自动分配的,由Flannel通过保存在Etcd服务中的记录确保它们不会重复
Doris
准备好装有Docker的虚拟机,这里我们部署Doris的最低配置的集群方式部署

按照官方所说,4台机器效果还可以,而且扩容也不难
1.下载doris的容器镜像
docker pull apachedoris/doris-dev:build-env-1.2
2.节点1配置FE(Leader)
创建一个Doris的容器节点,如果想外网访问该集群,需要配置端口映射,在–privileged 后面添加 -p 9030:9030等参数,具体参考官方文档,我这里就不开启了
docker run -it –name doris-node1 -h doris-node1 –network tech –privileged apachedoris/doris-dev:build-env-1.2
下载Doris的安装包
cd /opt
解压安装
tar -zxvf apache-doris-0.12.0-incubating-src.tar.gz
cd apache-doris-0.12.0-incubating-src
sh build.sh
配置该节点的FE(Leader)
cd output/fe
mkdir doris-meta
mkdir log
sh bin/start_fe.sh –daemon
这个 –daemon是后台运行的意思
运行之后检查一下,是否有doris的进行,监听的端口,日志信息等等
ps -ef

netstat -ntlp 如果没有netstat命令的话,执行以下yum install net-tools -y即可

vi log/fe.log

后续的节点配置运行之后,也要执行这些命令去检查一下状态,
3.节点2配置FE(Observer)和 BE
创建一个Doris的容器节点
docker run -it –name doris-node2 -h doris-node2 –network tech –privileged apachedoris/doris-dev:build-env-1.2
下载Doris的安装包
cd /opt
解压安装
tar -zxvf apache-doris-0.12.0-incubating-src.tar.gz
cd apache-doris-0.12.0-incubating-src
sh build.sh
配置该节点的FE(Observer)
cd output/fe
mkdir doris-meta
mkdir log
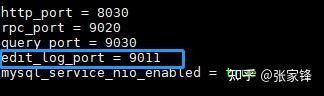
修改配置文件
vi conf/fe.conf
将edit_log_port的9010改成9011防止和Leader冲突
MySQL**连接Leader节点的FE(无密码),找一台装了mysql-client的节点去连,如果Leader节点是正常的情况下,是能后用mysql-client连接上的,没有的话自行找资料安装在Leader节点也可以**
mysql -uroot -h 192.168.124.9 -P 9030
-h**参数指定的IP为Leader节点的IP**
添加Observer的节点信息
这里的IP为Observer的IP和Observer节点的fe.conf中的edit_log_port后面的端口号
ALTER SYSTEM ADD OBSERVER “192.168.124.10:9011”;
启动Observer节点
这里的IP为Leader的IP以及Leader节点的fe.conf中的edit_log_port后面的端口号
sh bin/start_fe.sh –helper 192.168.124.9:9010 –daemon
按照配置节点1 的方式去检查一下状态
另外,检查一下Leader节点是否已经添加好了Observer
用mysql-client连接FE,执行这个语句:
SHOW PROC ‘/frontends’;

这时,查看fe.log的日志Leader和Observer都是不断滚动的,在通过心跳监测
Observer**日志**
Leader**的日志**
配置该节点的BE
cd ../be
mkdir storage
mkdir log
MySQL**连接节点一的FE(无密码)**
mysql -uroot -h 192.168.124.9 -P 9030
执行下面的语句
ALTER SYSTEM ADD BACKEND “192.168.124.10:9050”;
exit;
启动
sh bin/start_be.sh –daemon
检查BE的运行情况省略
4.节点3配置BE
创建一个Doris的容器节点
docker run -it –name doris-node3 -h doris-node3 –network tech –privileged apachedoris/doris-dev:build-env-1.2
下载Doris的安装包
cd /opt
解压安装
tar -zxvf apache-doris-0.12.0-incubating-src.tar.gz
cd apache-doris-0.12.0-incubating-src
sh build.sh
配置该节点的FE(Observer)
cd output/be
mkdir storage
mkdir log
MySQL**连接节点一的FE(无密码)**
mysql -uroot -h 192.168.124.9 -P 9030
ALTER SYSTEM ADD BACKEND “192.168.124.11:9050”;
exit;
启动
sh bin/start_be.sh –daemon
检查BE的运行情况省略
5.节点4配置BE
创建一个Doris的容器节点
docker run -it –name doris-node4 -h doris-node4 –network tech –privileged apachedoris/doris-dev:build-env-1.2
下载Doris的安装包
cd /opt
解压安装
tar -zxvf apache-doris-0.12.0-incubating-src.tar.gz
cd apache-doris-0.12.0-incubating-src
sh build.sh
配置该节点的FE(Observer)
cd output/be
mkdir storage
mkdir log
MySQL**连接节点一的FE(无密码)**
mysql -uroot -h 192.168.124.9 -P 9030
ALTER SYSTEM ADD BACKEND “192.168.124.12:9050”;
exit;
启动
sh bin/start_be.sh –daemon
检查BE的运行情况省略
6.查看BE状态
使用 mysql-client 连接到 FE,并执行 SHOW PROC ‘/backends’; 查看 BE 运行情况。如一切正常,isAlive 列应为 true。

查看 Follower 或 Observer 运行状态。使用 mysql-client 连接到任一已启动的 FE,并执行:SHOW PROC ‘/frontends’; 可以查看当前已加入集群的 FE 及其对应角色。

就按着这个步骤搭建吧
测试环境
硬件配置(3台X86服务器)
| CPU | Intel(R) Xeon(R) CPU E5-2650 0 @ 2.00GHz | |
|---|---|---|
软件环境
| 操作系统 | Centos 7.8 | |
|---|---|---|
数据量
会员数据,每天413万,两年数据31亿左右
测试查询语句
with mtable as (
select Jygs, Mkt Mkt, '' Channel, Sc Sc, Gz Gz, Dl Dl, Zl Zl, Xl Xl,
Ppid Ppid, Gdid Gdid, Gdname Gdname, Hylb, Hyxb, Hynl, '' Ecust, Hyid,
Xfsd Xfsd, Jzdj Jzdj,
count(distinct case hyid when '0' then Null else billno end) Hykds,
Sum(Hykjs) Hykjs,
Sum(Hyxfe) Hyxfe,
Sum(Hymle) Hymle,
count(distinct billno) Kds,
Sum(Kjs) Kjs,
Sum(Xfe) Xfe,
Sum(Kds - Hykds) + count(distinct case hyid when '0' then Null else hyid end ) Zxfrs,
Sum(mle) Mle,
Count(distinct case datediff(CAST(fkrq as date),cast('2016-01-01' as date)) when -1 then '0' when null then '0' else case Hyid when '0' then Null else Hyid end end) Xzhyrs,
Sum(case DATEDIFF(fkrq,'2016-01-01') when -1 then 0 else 1 end * Hyxfe) Xzhyxfe,
round(DATEDIFF(rq,'2016-01-01')/1,0)+1 as XFZQNUM,
concat_ws( '--' ,Min(Rq), Max(Rq)) Xfzqno --消费周期段
from (
Select
Jygs ,Mkt Mkt, '' Channel, Sc Sc, Gz Gz, Dl Dl, Zl Zl, Xl Xl,
Ppid Ppid, Gdid Gdid, Gdname Gdname, Hylb, Hyxb, Hynl, '' Ecust, Hyid,
Xfsd Xfsd, Jzdj Jzdj,Hyxfe,billno,Kjs,Xfe,Kds,Hykds,mle, 0 Xzhyxfe,Hykjs,Hymle,fkrq,rq
From dr_selllist_gd
Where
mkt in ('3004')
and rq BETWEEN '2016-01-01' and '2016-05-30'
And Zl = '002-302'
And Hylb in('001','002')
And Ppid = '002-023601'
And Xfsd = '08'
) a Group By Jygs, Mkt, Sc, Gz, Dl, Zl, Xl, Ppid, Gdid, Gdname, Hylb, Hyxb, Hynl, Hyid, Xfsd, Jzdj,rq
)
Select
Jygs,
Mkt Mkt,
'v3' Channel,
Sc Sc,
Gz Gz,
Dl Dl,
Zl Zl,
Xl Xl,
Ppid Ppid,
Gdid Gdid,
Gdname Gdname,
Hylb,
Hyxb,
Hynl,
'' Ecust,
Hyid,
Xfsd Xfsd,
Zkds,
Hykds,
Kdszb,
Zxfe,
Hyxfe,
Xfezb,
Zmle,
Hymle,
Mlezb,
Zkdj,
Hykdj,
Xfpc as Hyrs,
Zxfrs,
case Zxfrs when 0 then 0 else Round(Xfpc/Zxfrs, 2) end Hyxfrszb,
Xzhyrs,
Zkjs,
Hykjs,
Kjszb,
Zkjj,
Hykjj,
Xfpc,
Xzhyxfe,
XFZQNUM,
Xfzqno,
case Xfpc when 0 then 0 else Round(Hyxfe/Xfpc, 4) end Hygml,
case Xfpc when 0 then 0 else Round(Hykds / Xfpc, 4) end Hypjkds
From (
Select
Jygs,
Mkt,
Channel,
Sc,
Gz,
Dl,
Zl,
Xl,
Ppid,
Gdid,
Gdname,
Xfsd,
Hylb,
Hyxb,
Hynl,
Ecust,
Hyid,
(Kds) Zkds,
(Kjs) Zkjs,
(Xfe) Zxfe,
(Mle) Zmle,
(Zxfrs) Zxfrs,
Sum(Hykds) Hykds,
Sum(Hykjs) Hykjs,
Sum(Hyxfe) Hyxfe,
Sum(Hymle) Hymle,
case Kds when 0 then 0 else Round(Sum(Hykds)/Kds, 4) end Kdszb,
case Kjs when 0 then 0 else Round(Sum(Hykjs)/Kjs, 4) end Kjszb,
case Xfe when 0 then 0 else Round(Sum(Hyxfe)/Xfe, 4) end Xfezb,
case Mle when 0 then 0 else Round(Sum(Hymle)/Mle, 4) end Mlezb,
case Kds when 0 then 0 else Round(Xfe/Kds, 2) end Zkdj,
case Sum(Hykds) when 0 then 0 else Round(Sum(Hyxfe)/Sum(Hykds), 2) end Hykdj,
case Kjs when 0 then 0 else Round(Xfe/Kjs, 2) end Zkjj,
case Sum(Hykjs) when 0 then 0 else Round(Sum(Hyxfe)/Sum(Hykjs), 2) end Hykjj,
Count(Distinct (case Hyid when '0' then Null else Hyid end )) Xfpc,
Xzhyrs,
Sum(Xzhyxfe) Xzhyxfe,
XFZQNUM,
Xfzqno
From mtable
Group By Jygs,
Mkt,
Channel,
Sc,
Gz,
Dl,
Zl,
Xl,
Ppid,
Gdid,
Gdname,
Xfsd,
Hylb,
Hyxb,
Hynl,
Ecust,
Hyid,
Xfe,
Mle,
Kds,
Kjs,
Zxfrs,
XFZQNUM,
Xfzqno,Xzhyrs
) b
测试Case及结果
| 查询SQL说明 | 查询时间 |
|---|---|
在高并发的情况下查询等待时候会很长,这个主要原因可能是因为我这边是Docker部署,虚拟网络不是很熟,部署的性能不是很好,导致了很多查询一直在等待,
整体评估性能非常不错
数据建表语句
会员行为明细数据
create table dr_selllist_gd(
rq date,
mkt varchar(40),
hyid varchar(40),
hyno varchar(40),
hylb varchar(40),
hyxb varchar(40),
hynl varchar(40),
hyzy varchar(40),
hysr varchar(40),
hyxl varchar(40),
hyr varchar(40),
hyf varchar(40),
hym varchar(40),
sc varchar(40),
bm varchar(40),
gz varchar(40),
dl varchar(40),
zl varchar(40),
xl varchar(40),
ppid varchar(40),
supid varchar(40),
gdid varchar(40),
invno varchar(40),
kds decimal(20,2),
xfe decimal(20,4),
mle decimal(20,4),
hykds decimal(20,2),
hyxfe decimal(20,4),
hymle decimal(20,4),
hdhys decimal(20,4),
num1 decimal(20,4),
num2 decimal(20,4),
num3 decimal(20,4),
num4 decimal(20,4),
num5 decimal(20,4),
num6 decimal(20,4),
num7 decimal(20,4),
num8 decimal(20,4),
num9 decimal(20,4),
gzlx varchar(50),
gdname varchar(200),
custname varchar(200),
ldfs varchar(100),
jzqy varchar(100),
addattr2 varchar(100),
addattr3 varchar(100),
addattr4 varchar(100),
khjl varchar(100),
jzdj varchar(100),
ssd varchar(100),
telyys varchar(100),
billno varchar(50),
syjid varchar(100),
cyid varchar(20),
kjs int,
hykjs int,
hyqy varchar(40),
xfsd varchar(40),
ld varchar(40),
lc varchar(40),
ppdj varchar(40),
xz varchar(40),
xx varchar(40),
jr varchar(40),
fkrq date,
jygs varchar(20),
rqyear int,
rqmonth int,
channel varchar(20),
ecust varchar(20),
regmkt varchar(20),
hybirth varchar(20)
)
DUPLICATE KEY(rq,mkt,hyid)
PARTITION BY RANGE(rq) (
PARTITION P_201801 VALUES [("2017-01-01"),("2017-02-01")),
PARTITION P_201801 VALUES [("2017-02-01"),("2017-03-01")),
PARTITION P_201801 VALUES [("2017-03-01"),("2017-04-01")),
PARTITION P_201801 VALUES [("2017-04-01"),("2017-05-01")),
PARTITION P_201801 VALUES [("2017-05-01"),("2017-06-01")),
PARTITION P_201801 VALUES [("2017-06-01"),("2017-07-01")),
PARTITION P_201801 VALUES [("2017-07-01"),("2017-08-01"))
)
DISTRIBUTED BY HASH(mkt) BUCKETS 112
PROPERTIES(
"replication_num" = "2",
"in_memory"="true",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "MONTH",
"dynamic_partition.start" = "-2147483648",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "P_",
"dynamic_partition.buckets" = "112"
);
动态添加分区
ALTER TABLE dr_selllist_gd ADD PARTITION P_201806 VALUES LESS THAN("2018-07-01");
ALTER TABLE dr_selllist_gd ADD PARTITION P_201807 VALUES LESS THAN("2018-08-01");
ALTER TABLE dr_selllist_gd ADD PARTITION P_201808 VALUES LESS THAN("2018-09-01");
ALTER TABLE dr_selllist_gd ADD PARTITION P_201809 VALUES LESS THAN("2018-10-01");
ALTER TABLE dr_selllist_gd ADD PARTITION P_201810 VALUES LESS THAN("2018-11-01");
ALTER TABLE dr_selllist_gd ADD PARTITION P_201811 VALUES LESS THAN("2018-12-01");
ALTER TABLE dr_selllist_gd ADD PARTITION P_201812 VALUES LESS THAN("2019-01-01");
使用手册
ROLLUP使用
Rollup只能在Aggregate,Uniq模型上使用,不能再Duplicate使用
创建删除语法
rollup 支持如下几种创建方式:
1. 创建 rollup index
语法:
ADD ROLLUP rollup_name (column_name1, column_name2, ...)
[FROM from_index_name]
[PROPERTIES ("key"="value", ...)]
properties: 支持设置超时时间,默认超时时间为1天。
例子:
ADD ROLLUP r1(col1,col2) from r0
1.2 批量创建 rollup index
语法:
ADD ROLLUP [rollup_name (column_name1, column_name2, ...)
[FROM from_index_name]
[PROPERTIES ("key"="value", ...)],...]
例子:
ADD ROLLUP r1(col1,col2) from r0, r2(col3,col4) from r0
1.3 注意:
1) 如果没有指定 from_index_name,则默认从 base index 创建
2) rollup 表中的列必须是 from_index 中已有的列
3) 在 properties 中,可以指定存储格式。具体请参阅 CREATE TABLE
2. 删除 rollup index
语法:
DROP ROLLUP rollup_name [PROPERTIES ("key"="value", ...)]
例子:
DROP ROLLUP r1
2.1 批量删除 rollup index
语法:DROP ROLLUP [rollup_name [PROPERTIES ("key"="value", ...)],...]
例子:DROP ROLLUP r1,r2
2.2 注意:
1) 不能删除 base index
示例
首先我们先创建Base 表
CREATE TABLE IF NOT EXISTS expamle_tbl
(
`user_id` LARGEINT NOT NULL,
`date` DATE NOT NULL,
`city` VARCHAR(20),
`age` SMALLINT,
`sex` TINYINT,
`last_visit_date` DATETIME REPLACE DEFAULT "2020-08-12 00:00:00" ,
`cost` BIGINT SUM DEFAULT "0" ,
`max_dwell_time` INT MAX DEFAULT "0",
`min_dwell_time` INT MIN DEFAULT "99999"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`) (
PARTITION P_202008 VALUES [("2020-08-01"),("2020-09-01"))
)
DISTRIBUTED BY HASH(`city`) BUCKETS 2
PROPERTIES(
"replication_num" = "2"
);
然后在Base表上创建Rollup
ALTER TABLE expamle_tbl
ADD ROLLUP example_rollup_index(user_id, date, cost)
PROPERTIES("storage_type"="column");
ALTER TABLE expamle_tbl
ADD ROLLUP cost_rollup_index(user_id, cost)
PROPERTIES("storage_type"="column");
ALTER TABLE expamle_tbl
ADD ROLLUP dwell_rollup_index(user_id,date, max_dwell_time,min_dwell_time)
PROPERTIES("storage_type"="column");
在mysql命令下可以看到我们创建的rollup
然后倒入数据就可以进行查询了,示例数据如下:
10000,2020-08-01,北京,20,0,2020-08-01 06:00:00,20,10,10
10000,2020-08-01,北京,20,0,2020-08-01 07:00:00,15,2,2
10001,2020-08-01,北京,30,1,2020-08-01 17:05:45,2,22,22
10002,2020-08-02,上海,20,1,2020-08-02 12:59:12,200,5,5
10003,2020-08-02,广州,32,0,2020-08-02 11:20:00,30,11,11
10004,2020-08-01,深圳,35,0,2020-08-01 10:00:15,100,3,3
10004,2020-08-03,深圳,35,0,2020-08-03 10:20:22,11,6,6
10000,2020-08-04,北京,20,0,2020-08-04 06:00:00,20,10,10
10000,2020-08-04,北京,20,0,2020-08-04 07:00:00,15,2,2
10001,2020-08-04,北京,30,1,2020-08-04 17:05:45,2,22,22
10002,2020-08-04,上海,20,1,2020-08-04 12:59:12,200,5,5
10003,2020-08-04,广州,32,0,2020-08-04 11:20:00,30,11,11
10004,2020-08-04,深圳,35,0,2020-08-04 10:00:15,100,3,3
10004,2020-08-04,深圳,35,0,2020-08-04 10:20:22,11,6,6
10000,2020-08-05,北京,20,0,2020-08-05 06:00:00,20,10,10
10000,2020-08-05,北京,20,0,2020-08-05 07:00:00,15,2,2
10001,2020-08-05,北京,30,1,2020-08-05 17:05:45,2,22,22
10002,2020-08-05,上海,20,1,2020-08-05 12:59:12,200,5,5
10003,2020-08-05,广州,32,0,2020-08-05 11:20:00,30,11,11
10004,2020-08-05,深圳,35,0,2020-08-05 10:00:15,100,3,3
10004,2020-08-05,深圳,35,0,2020-08-05 10:20:22,11,6,6
使用Segment V2 存储格式
V2版本支持一下新特性:
- bitmap 索引
- 内存表
- page cache
- 字典压缩
- 延迟物化(Lazy Materialization)
版本支持
从0.12版本开始支持V2数据格式
使用下面这个版本编译:
https://github.com/baidu-doris/incubator-doris/tree/DORIS-0.12.12-release
启用方法
default_rowset_type:FE 一个全局变量(Global Variable)设置,默认为 “alpha”,即 V1 版本。default_rowset_type:BE 的一个配置项,默认为 “ALPHA”,即 V1 版本。
- 从 BE 开启全量格式转换
在
be.conf中添加变量default_rowset_type=BETA并重启 BE 节点。在之后的 compaction 流程中,数据会自动从 V1 转换成 V2。 - 从 FE 开启全量格式转换
通过 mysql 客户端连接 Doris 后,执行如下语句:
SET GLOBAL default_rowset_type = beta;执行完成后,FE 会通过心跳将信息发送给 BE,之后 BE 的 compaction 流程中,数据会自动从 V1 转换成 V2。
数据模型、ROLLUP 及前缀索引
在 Doris 中,数据以表(Table)的形式进行逻辑上的描述。 一张表包括行(Row)和列(Column)。Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。
Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应维度列和指标列。
Doris 的数据模型主要分为3类:
- Aggregate
- Uniq
- Duplicate
Aggregate 模型
当我们导入数据时,对于 Key 列相同的行和聚合成一行,而 Value 列会按照设置的 AggregationType 进行聚合。 AggregationType 目前有以下四种聚合方式:
- SUM:求和,多行的 Value 进行累加。
- REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
- MAX:保留最大值。
- MIN:保留最小值。
示例:
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间",
)
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
... /* 省略 Partition 和 Distribution 信息 */
表中的列按照是否设置了 AggregationType,分为 Key (维度列) 和 Value(指标列)。没有设置 AggregationType 的,如 user_id、date、age … 等称为 Key,而设置了 AggregationType 的称为 Value。
数据的聚合,在 Doris 中有如下三个阶段发生:
- 每一批次数据导入的 ETL 阶段。该阶段会在每一批次导入的数据内部进行聚合。
- 底层 BE 进行数据 Compaction 的阶段。该阶段,BE 会对已导入的不同批次的数据进行进一步的聚合。
- 数据查询阶段。在数据查询时,对于查询涉及到的数据,会进行对应的聚合。
数据在不同时间,可能聚合的程度不一致。比如一批数据刚导入时,可能还未与之前已存在的数据进行聚合。但是对于用户而言,用户只能查询到聚合后的数据。即不同的聚合程度对于用户查询而言是透明的。用户需始终认为数据以最终的完成的聚合程度存在,而不应假设某些聚合还未发生。(可参阅聚合模型的局限性一节获得更多详情。
Uniq 模型
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。因此,引入了 Uniq 的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式
Duplicate 模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求。因此,我们引入 Duplicate 数据模型来满足这类需求
这种数据模型区别于 Aggregate 和 Uniq 模型。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序。(更贴切的名称应该为 “Sorted Column”,这里取名 “DUPLICATE KEY” 只是用以明确表示所用的数据模型。)。在 DUPLICATE KEY 的选择上,我们建议适当的选择前 2-4 列就可以
Doris优化
##设置执行内存
set global exec_mem_limit=2147483648;
##设置查询缓存
set global query_cache_type=1;
set global query_cache_size=134217728;
##设置查询超时时间60秒,默认300秒
set global query_timeout = 60;
###记录sql执行日志
set global is_report_success=true;
##启用V2数据存储格式
SET GLOBAL default_rowset_type = beta;
##设置时区
SET global time_zone = 'Asia/Shanghai'
##启用fe动态分区
ADMIN SET FRONTEND CONFIG ("dynamic_partition_enable" = "true")
数据导入
Kafka数据导入
- 支持无认证的 Kafka 访问,以及通过 SSL 方式认证的 Kafka 集群。
- 支持的消息格式为 csv 文本格式。每一个 message 为一行,且行尾不包含换行符。
- 仅支持 Kafka 0.10.0.0(含) 以上版本
示例
CREATE ROUTINE LOAD retail1.kafka123 on dr_selllist_gd_kafka
PROPERTIES
(
"desired_concurrent_number"="1"
)
FROM KAFKA
(
"kafka_broker_list"= "192.168.9.22:6667,192.168.9.23:6667",
"kafka_topic" = "selllist"
);
Insert Into
Insert Into 语句的使用方式和 MySQL 等数据库中 Insert Into 语句的使用方式类似。但在 Doris 中,所有的数据写入都是一个独立的导入作业。所以这里将 Insert Into 也作为一种导入方式介绍。
主要的 Insert Into 命令包含以下两种;
- INSERT INTO tbl SELECT …
- INSERT INTO tbl (col1, col2, …) VALUES (1, 2, …), (1,3, …);
其中第二种命令仅用于 Demo,不要使用在测试或生产环境中
导入语法:
INSERT INTO table_name [WITH LABEL label] [partition_info] [col_list] [query_stmt] [VALUES];
示例:
INSERT INTO tbl2 WITH LABEL label1 SELECT * FROM tbl3;
INSERT INTO tbl1 VALUES ("qweasdzxcqweasdzxc"), ("a");
注意
当需要使用 CTE(Common Table Expressions) 作为 insert 操作中的查询部分时,必须指定 WITH LABEL 和 column list 部分。示例
INSERT INTO tbl1 WITH LABEL label1
WITH cte1 AS (SELECT * FROM tbl1), cte2 AS (SELECT * FROM tbl2)
SELECT k1 FROM cte1 JOIN cte2 WHERE cte1.k1 = 1;
INSERT INTO tbl1 (k1)
WITH cte1 AS (SELECT * FROM tbl1), cte2 AS (SELECT * FROM tbl2)
SELECT k1 FROM cte1 JOIN cte2 WHERE cte1.k1 = 1;
- partition_info 导入表的目标分区,如果指定目标分区,则只会导入符合目标分区的数据。如果没有指定,则默认值为这张表的所有分区。
- col_list 导入表的目标列,可以以任意的顺序存在。如果没有指定目标列,那么默认值是这张表的所有列。如果待表中的某个列没有存在目标列中,那么这个列需要有默认值,否则 Insert Into 就会执行失败。 如果查询语句的结果列类型与目标列的类型不一致,那么会调用隐式类型转化,如果不能够进行转化,那么 Insert Into 语句会报语法解析错误。
- query_stmt 通过一个查询语句,将查询语句的结果导入到 Doris 系统中的其他表。查询语句支持任意 Doris 支持的 SQL 查询语法。
- VALUES 用户可以通过 VALUES 语法插入一条或者多条数据。 注意:VALUES 方式仅适用于导入几条数据作为导入 DEMO 的情况,完全不适用于任何测试和生产环境。Doris 系统本身也不适合单条数据导入的场景。建议使用 INSERT INTO SELECT 的方式进行批量导入。
- WITH LABEL INSERT 操作作为一个导入任务,也可以指定一个 label。如果不指定,则系统会自动指定一个 UUID 作为 label。 注意:建议指定 Label 而不是由系统自动分配。如果由系统自动分配,但在 Insert Into 语句执行过程中,因网络错误导致连接断开等,则无法得知 Insert Into 是否成功。而如果指定 Label,则可以再次通过 Label 查看任务结果
导入结果
Insert Into 本身就是一个 SQL 命令,其返回结果会根据执行结果的不同,分为以下几种:
-
结果集为空 如果 insert 对应 select 语句的结果集为空,则返回如下: mysql> insert into tbl1 select * from empty_tbl; Query OK, 0 rows affected (0.02 sec)
Query OK表示执行成功。0 rows affected表示没有数据被导入。 -
结果集不为空 在结果集不为空的情况下。返回结果分为如下几种情况:
-
- Insert 执行成功并可见:
mysql> insert into tbl1 select * from tbl2; Query OK, 4 rows affected (0.38 sec) {‘label’:’insert_8510c568-9eda-4173-9e36-6adc7d35291c’, ‘status’:’visible’, ‘txnId’:’4005’} mysql> insert into tbl1 with label my_label1 select * from tbl2; Query OK, 4 rows affected (0.38 sec) {‘label’:’my_label1’, ‘status’:’visible’, ‘txnId’:’4005’} mysql> insert into tbl1 select * from tbl2; Query OK, 2 rows affected, 2 warnings (0.31 sec) {‘label’:’insert_f0747f0e-7a35-46e2-affa-13a235f4020d’, ‘status’:’visible’, ‘txnId’:’4005’} mysql> insert into tbl1 select * from tbl2; Query OK, 2 rows affected, 2 warnings (0.31 sec) {‘label’:’insert_f0747f0e-7a35-46e2-affa-13a235f4020d’, ‘status’:’committed’, ‘txnId’:’4005’}
Query OK表示执行成功。4 rows affected表示总共有4行数据被导入。2 warnings表示被过滤的行数。 同时会返回一个 json 串: {‘label’:’my_label1’, ‘status’:’visible’, ‘txnId’:’4005’} {‘label’:’insert_f0747f0e-7a35-46e2-affa-13a235f4020d’, ‘status’:’committed’, ‘txnId’:’4005’} {‘label’:’my_label1’, ‘status’:’visible’, ‘txnId’:’4005’, ‘err’:’some other error’}label为用户指定的 label 或自动生成的 label。Label 是该 Insert Into 导入作业的标识。每个导入作业,都有一个在单 database 内部唯一的 Label。status表示导入数据是否可见。如果可见,显示visible,如果不可见,显示committed。txnId为这个 insert 对应的导入事务的 id。err字段会显示一些其他非预期错误。 当需要查看被过滤的行时,用户可以通过如下语句 show load where label=”xxx”; 返回结果中的 URL 可以用于查询错误的数据,具体见后面 查看错误行 小结。 数据不可见是一个临时状态,这批数据最终是一定可见的 可以通过如下语句查看这批数据的可见状态: show transaction where id=4005; 返回结果中的TransactionStatus列如果为visible,则表述数据可见
- Insert 执行成功并可见:
mysql> insert into tbl1 select * from tbl2; Query OK, 4 rows affected (0.38 sec) {‘label’:’insert_8510c568-9eda-4173-9e36-6adc7d35291c’, ‘status’:’visible’, ‘txnId’:’4005’} mysql> insert into tbl1 with label my_label1 select * from tbl2; Query OK, 4 rows affected (0.38 sec) {‘label’:’my_label1’, ‘status’:’visible’, ‘txnId’:’4005’} mysql> insert into tbl1 select * from tbl2; Query OK, 2 rows affected, 2 warnings (0.31 sec) {‘label’:’insert_f0747f0e-7a35-46e2-affa-13a235f4020d’, ‘status’:’visible’, ‘txnId’:’4005’} mysql> insert into tbl1 select * from tbl2; Query OK, 2 rows affected, 2 warnings (0.31 sec) {‘label’:’insert_f0747f0e-7a35-46e2-affa-13a235f4020d’, ‘status’:’committed’, ‘txnId’:’4005’}
相关配置
- timeout
导入任务的超时时间(以秒为单位),导入任务在设定的 timeout 时间内未完成则会被系统取消,变成 CANCELLED。
目前 Insert Into 并不支持自定义导入的 timeout 时间,所有 Insert Into 导入的超时时间是统一的,默认的 timeout 时间为1小时。如果导入的源文件无法再规定时间内完成导入,则需要调整 FE 的参数
insert_load_default_timeout_second。 同时 Insert Into 语句收到 Session 变量query_timeout的限制。可以通过SET query_timeout = xxx;来增加超时时间,单位是秒。 - enable_insert_strict
Insert Into 导入本身不能控制导入可容忍的错误率。用户只能通过
enable_insert_strict这个 Session 参数用来控制。 当该参数设置为 false 时,表示至少有一条数据被正确导入,则返回成功。如果有失败数据,则还会返回一个 Label。 当该参数设置为 true 时,表示如果有一条数据错误,则导入失败。 默认为 false。可通过SET enable_insert_strict = true;来设置。 - query_timeout
Insert Into 本身也是一个 SQL 命令,因此 Insert Into 语句也受到 Session 变量
query_timeout的限制。可以通过SET query_timeout = xxx;来增加超时时间,单位是秒
数据量
insert Into 对数据量没有限制,大数据量导入也可以支持。但 Insert Into 有默认的超时时间,用户预估的导入数据量过大,就需要修改系统的 Insert Into 导入超时时间。
导入数据量 = 36G 约≤ 3600s * 10M/s
其中 10M/s 是最大导入限速,用户需要根据当前集群情况计算出平均的导入速度来替换公式中的 10M/s
常见问题
查看错误行
由于 Insert Into 无法控制错误率,只能通过 enable_insert_strict 设置为完全容忍错误数据或完全忽略错误数据。因此如果 enable_insert_strict 设为 true,则 Insert Into 可能会失败。而如果 enable_insert_strict 设为 false,则可能出现仅导入了部分合格数据的情况。
当返回结果中提供了 url 字段时,可以通过以下命令查看错误行:
SHOW LOAD WARNINGS ON "url";
示例:
SHOW LOAD WARNINGS ON "http://ip:port/api/_load_error_log?file=__shard_13/error_log_insert_stmt_d2cac0a0a16d482d-9041c949a4b71605_d2cac0a0a16d482d_9041c949a4b71605";
错误的原因通常如:源数据列长度超过目的数据列长度、列类型不匹配、分区不匹配、列顺序不匹配等等。
Stream Load
tream load 是一个同步的导入方式,用户通过发送 HTTP 协议发送请求将本地文件或数据流导入到 Doris 中。Stream load 同步执行导入并返回导入结果。用户可直接通过请求的返回体判断本次导入是否成功。
Stream load 主要适用于导入本地文件,或通过程序导入数据流中的数据。
Stream load 通过 HTTP 协议提交和传输数据。这里通过 curl 命令展示如何提交导入。
用户也可以通过其他 HTTP client 进行操作。
curl --location-trusted -u user:passwd [-H ""...] -T data.file -XPUT http://fe_host:http_port/api/{db}/{table}/_stream_load
Header 中支持属性见下面的 ‘导入任务参数’ 说明
格式为: -H "key1:value1"
用户无法手动取消 Stream load,Stream load 在超时或者导入错误后会被系统自动取消
签名参数
- user/passwd Stream load 由于创建导入的协议使用的是 HTTP 协议,通过 Basic access authentication 进行签名。Doris 系统会根据签名验证用户身份和导入权限。
导入任务参数
Stream load 由于使用的是 HTTP 协议,所以所有导入任务有关的参数均设置在 Header 中。下面主要介绍了 Stream load 导入任务参数的部分参数意义。
- label 导入任务的标识。每个导入任务,都有一个在单 database 内部唯一的 label。label 是用户在导入命令中自定义的名称。通过这个 label,用户可以查看对应导入任务的执行情况。 label 的另一个作用,是防止用户重复导入相同的数据。强烈推荐用户同一批次数据使用相同的 label。这样同一批次数据的重复请求只会被接受一次,保证了 At-Most-Once 当 label 对应的导入作业状态为 CANCELLED 时,该 label 可以再次被使用。
- max_filter_ratio
导入任务的最大容忍率,默认为0容忍,取值范围是0~1。当导入的错误率超过该值,则导入失败。
如果用户希望忽略错误的行,可以通过设置这个参数大于 0,来保证导入可以成功。
计算公式为:
(dpp.abnorm.ALL / (dpp.abnorm.ALL + dpp.norm.ALL ) ) > max_filter_ratiodpp.abnorm.ALL表示数据质量不合格的行数。如类型不匹配,列数不匹配,长度不匹配等等。dpp.norm.ALL指的是导入过程中正确数据的条数。可以通过SHOW LOAD命令查询导入任务的正确数据量。 原始文件的行数 =dpp.abnorm.ALL + dpp.norm.ALL - where
导入任务指定的过滤条件。Stream load 支持对原始数据指定 where 语句进行过滤。被过滤的数据将不会被导入,也不会参与 filter ratio 的计算,但会被计入
num_rows_unselected。 - partition
待导入表的 Partition 信息,如果待导入数据不属于指定的 Partition 则不会被导入。这些数据将计入
dpp.abnorm.ALL - columns 待导入数据的函数变换配置,目前 Stream load 支持的函数变换方法包含列的顺序变化以及表达式变换,其中表达式变换的方法与查询语句的一致。 列顺序变换例子:原始数据有两列,目前表也有两列(c1,c2)但是原始文件的第一列对应的是目标表的c2列, 而原始文件的第二列对应的是目标表的c1列,则写法如下: columns: c2,c1 表达式变换例子:原始文件有两列,目标表也有两列(c1,c2)但是原始文件的两列均需要经过函数变换才能对应目标表的两列,则写法如下: columns: tmp_c1, tmp_c2, c1 = year(tmp_c1), c2 = month(tmp_c2) 其中 tmp_*是一个占位符,代表的是原始文件中的两个原始列。
- exec_mem_limit 导入内存限制。默认为 2GB,单位为字节。
- strict_mode
Stream load 导入可以开启 strict mode 模式。开启方式为在 HEADER 中声明
strict_mode=true。默认的 strict mode 为关闭。 strict mode 模式的意思是:对于导入过程中的列类型转换进行严格过滤。严格过滤的策略如下:
- 对于列类型转换来说,如果 strict mode 为true,则错误的数据将被 filter。这里的错误数据是指:原始数据并不为空值,在参与列类型转换后结果为空值的这一类数据。
- 对于导入的某列由函数变换生成时,strict mode 对其不产生影响。
- 对于导入的某列类型包含范围限制的,如果原始数据能正常通过类型转换,但无法通过范围限制的,strict mode 对其也不产生影响。例如:如果类型是 decimal(1,0), 原始数据为 10,则属于可以通过类型转换但不在列声明的范围内。这种数据 strict 对其不产生影响。
相关参数
FE参数配置
- stream_load_default_timeout_second
导入任务的超时时间(以秒为单位),导入任务在设定的 timeout 时间内未完成则会被系统取消,变成 CANCELLED。
默认的 timeout 时间为 600 秒。如果导入的源文件无法在规定时间内完成导入,用户可以在 stream load 请求中设置单独的超时时间。
或者调整 FE 的参数stream_load_default_timeout_second 来设置全局的默认超时时间
BE参数配置
- streaming_load_max_mb
Stream load 的最大导入大小,默认为 10G,单位是 MB。如果用户的原始文件超过这个值,则需要调整 BE 的参数 streaming_load_max_mb
数据量
由于 Stream load 的原理是由 BE 发起的导入并分发数据,建议的导入数据量在 1G 到 10G 之间。由于默认的最大 Stream load 导入数据量为 10G,所以如果要导入超过 10G 的文件需要修改 BE 的配置 streaming_load_max_mb
比如:待导入文件大小为15G
修改 BE 配置 streaming_load_max_mb 为 16000 即可。
Stream load 的默认超时为 300秒,按照 Doris 目前最大的导入限速来看,约超过 3G 的文件就需要修改导入任务默认超时时间了。
导入任务超时时间 = 导入数据量 / 10M/s (具体的平均导入速度需要用户根据自己的集群情况计算)
例如:导入一个 10G 的文件
timeout = 1000s 等于 10G / 10M/s
Mini load
curl –location-trusted -u root: -T /data09/csv/2017/2017-06-01.csv http://drois01:8030/api/retail/dr_selllist_gd/_load?label=2017-06-01&column_separator=%2c
导入文件格式为CSV,
column_separator:表示字段分隔符
label:每个批次的label,要全局唯一
-T 要导入的文件
-u:导入任务的签名,用户名密码,用户名密码用英文分号分割
retail/dr_selllist_gd: 分别是你要导入数据的数据库及数据表
Broker Load
Broker load 是一个异步的导入方式,支持的数据源取决于 Broker 进程支持的数据源。
用户需要通过 MySQL 协议 创建 Broker load 导入,并通过查看导入命令检查导入结果
Spark Load
Spark load 通过 Spark 实现对导入数据的预处理,提高 Doris 大数据量的导入性能并且节省 Doris 集群的计算资源。主要用于初次迁移,大数据量导入 Doris 的场景。
Spark load 是一种异步导入方式,用户需要通过 MySQL 协议创建 Spark 类型导入任务,并通过 SHOW LOAD 查看导入结果。
查询设置
查询超时
当前默认查询时间设置为最长为 300 秒,如果一个查询在 300 秒内没有完成,则查询会被 Doris 系统 cancel 掉。用户可以通过这个参数来定制自己应用的超时时间,实现类似 wait(timeout) 的阻塞方式。
查看当前超时设置:
| mysql> SHOW VARIABLES LIKE “%query_timeout%”; +—————+——-+ | Variable_name | Value | +—————+——-+ | QUERY_TIMEOUT | 300 | +—————+——-+ 1 row in set (0.00 sec) 修改超时时间到1分钟: |
SET query_timeout = 60;
当前超时的检查间隔为 5 秒,所以小于 5 秒的超时不会太准确。 以上修改同样为 session 级别。可以通过 SET GLOBAL 修改全局有效
SQL语句规则
Doris对表名,字段名称严格区分大小写
Doris所有子查询必须带别名
BE磁盘间负载均衡
drop_backend_after_decommission
该配置用于控制系统在成功下线(Decommission) BE 后,是否 Drop 该 BE。如果为 true,则在 BE 成功下线后,会删除掉该BE节点。如果为 false,则在 BE 成功下线后,该 BE 会一直处于 DECOMMISSION 状态,但不会被删除。
该配置在某些场景下可以发挥作用。假设一个 Doris 集群的初始状态为每个 BE 节点有一块磁盘。运行一段时间后,系统进行了纵向扩容,即每个 BE 节点新增2块磁盘。因为 Doris 当前还不支持 BE 内部各磁盘间的数据均衡,所以会导致初始磁盘的数据量可能一直远高于新增磁盘的数据量。此时我们可以通过以下操作进行人工的磁盘间均衡:
- 将该配置项置为 false。
- 对某一个 BE 节点,执行 decommission 操作,该操作会将该 BE 上的数据全部迁移到其他节点中。
- decommission 操作完成后,该 BE 不会被删除。此时,取消掉该 BE 的 decommission 状态。则数据会开始从其他 BE 节点均衡回这个节点。此时,数据将会均匀的分布到该 BE 的所有磁盘上。
- 对所有 BE 节点依次执行 2,3 两个步骤,最终达到所有节点磁盘均衡的目的
V2存储格式的启用
如果遇到BE宕机异常请参照下面的处理方式
https://github.com/apache/incubator-doris/pull/3791
并使用下面这个版本
https://github.com/baidu-doris/incubator-doris/tree/DORIS-0.12.12-release




