
基于Apache doris怎么构建数据中台(四)-数据接入系统
上一次我们讲解了数据资产,元数据管理,血缘关系等,这次我们开始将数据接入,怎么实现快速的数据接入
在开发数据模型时,我们必须有一个统一的平台,能够像流水线一样,把数据一步步加工成数据模型。这其中涉及到数据萃取、数据聚合、作业调度等。
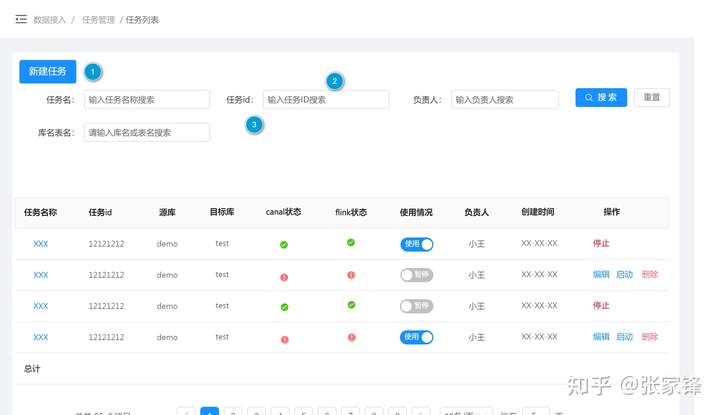
主要是为了实现业务数据的快速接入,零代码实现,数据分析人员只需要通过UI进行简单的配置、提交任务即可完成数据的接入,并能实现对数据接入任务的管理及监控。
Mysql数据源数据接入
主要是为了完成针对Mysql数据的业务系统数据接入零代码实现,不需要开发人员接入,提供给数据分析人员使用,目的是为了业务数据快速接入,无需编码
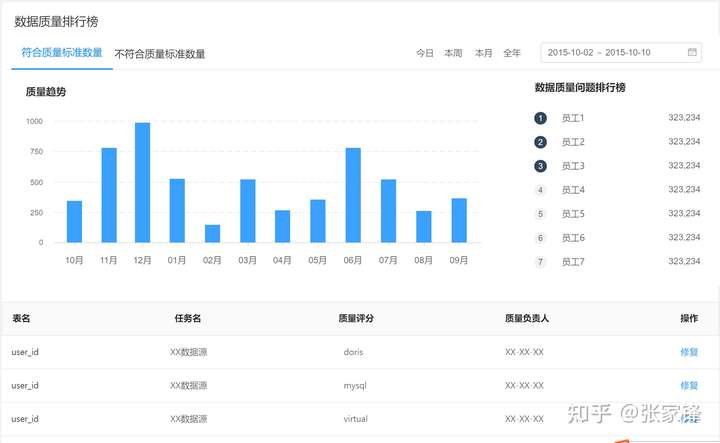
数据接入系统我们通过自研的规则引擎,和接入任务整合,同时自动化完成了数据接入的ETL工作,规则可以通过页面进行可视化配置,这块我会在后面的质量模块介绍
- 通过UI界面添加数据接入任务的方式
- Mysql数据的采集是通过Canal 采集binlog完成
- 在界面上第一步是配置canal实例(canal实例的管理是通过cannal admin),除了kafka topic名称需要手工输入,其他信息尽可能不要让使用人员手工数据
- 第二步配置Flink Job任务信息,需要的kafka topic名称来源于上一步,业务表和数仓表的对应关系通过元数据选择方式完成,避免手工输入
- 第三步:提交任务,这时候完成canal实例创建,运行,Flink job任务提交运行
- 并在列表上监控canal实例及Flink job运行状态的监控
DataX 数据接入
要实现的内容基本和Mysql binlog的同步一样
只不过是Datax是为了实现非mysql数据的数据接入零代码完成
数据API方式数据接入
传统数据API方式的数据接入都需要进行代码开发对接才能完成,初步设想这块通过通用的代码生成器的方式实现针对常用API方式(WebService,RestFul API)零代码接入
图形化数据接入
我们目前支持Kafka,Mysql,datax数据零代码接入
Mysql :通过Canal采集业务数据库的binlog日志,将数据推送到指定的Kafka队列
其他DB:通过datax(全量和增量)定时的将数据,推送到指定的Kafka队列,这里我们对Datax做了改造,让Datax的数据格式和Canal格式一致,
数据接口:后端数据接收服务队数据进行转换(可配置)以后,形成和Canal一致的数据格式,推送到指定的Kafka队列
- 后端针对业务db,我们会通过元数据采集系统采集业务系统库表及字段的元数据信息,进入到元数据管理系
- 针对没有数据库表的,通过接口直接推送到Kafka的数据,我们在元数据管理里统一提供虚拟库表,通过这个完成数据的统一接入
- 在数据接入的时候,我们整合了我们自研的规则引擎,可以实现数据接入和ETL规则自动绑定,通过阿波罗配置系统进行统一下推到Flink Job里执行,
- 对于异常数据(不符合规则的),自动推送到指定的Kafka队列,后端有对应的服务进行处理,我们这里是通过Flink实现了一个轻量级的ETL,及数据入Doris的自动化工具
效果如下:
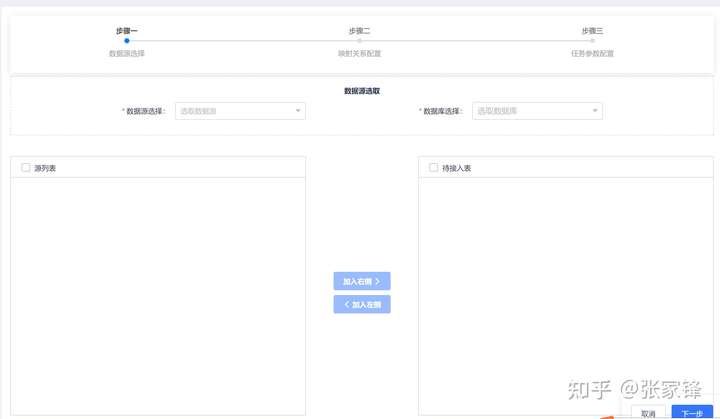
第一步选择要接入的数据表
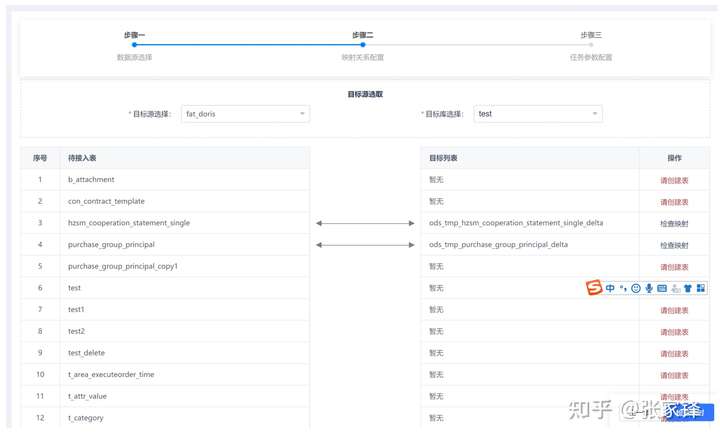
第二步选择数据仓相关的信息,这一步会进行表字段映射检查及配置,目前要首先在数仓中建立相应的表,后续会自动化建表
第三步就是输入Flink Job名称进行提交了,整个就完成了
数据开发控制台
- 提供一个数据类似于HUE的SQL数据开发控制台,数据开发人员可以通过这个控制台进行sql的开发调试
- 生产环境这里delete,drop等操作要进行审批确认,才能进行,避免误操作,删除数据
- 可以将调试好的sql,添加到定时任务调度系统中,这里我们将海豚调度集成到我们数据中台中
零代码入仓的问题解答
很多朋友问到,我们这种方式会不会数据丢失,会不会数据重复,结合我们自己的场景,给我我们的解决方案
数据入到Doris数据仓库对应的表中,这里我们采用的是Flink实时消费KafKa的数据,然后通过Doris的 Stream Load完成
Flink消费Kafka数据我们支持两种方式:
-
指定Kafka Topic的Offset进行消费:kafka.offset
-
指定时间戳的方式:kafka.timestamp
数据丢失的问题
针对Flink Job失败,重启也是通过这两个参数,
- 如果你记录了失败的时间点的Kafka Offset,可以通过配置文件配置这个参数来重启Flink Job就
行。这样不会造成数据丢失
- 如果没有记录这个offset,可通过指定consumer.setStartFromTimestamp(timestamp);这个时间就是在配置文件中配置的时间戳 ,这样无论是通过offset还是从指定的时间开始消费Kafka数据,都不会造成数据丢失
数据重复问题
因为我们这个是在数据接入层使用的,数据是进入到数据仓ODS层,在这一层我们采用的是Doris Unique Key模型,就算数据重复入库,会覆盖原先的数据,不会存在数据重复问
下一讲开始讲解数据质量管理




