
Apache Doris Stream load 数据导入
1.概要
Stream load 是一个同步的导入方式,用户通过发送 HTTP 协议发送请求将本地文件或数据流导入到 Doris 中。Stream load 同步执行导入并返回导入结果。用户可直接通过请求的返回体判断本次导入是否成功。
Stream load 主要适用于导入本地文件,或通过程序导入数据流中的数据。
Broker load 支持文件类型:文本和JSON两个格式的数据
2. 原理
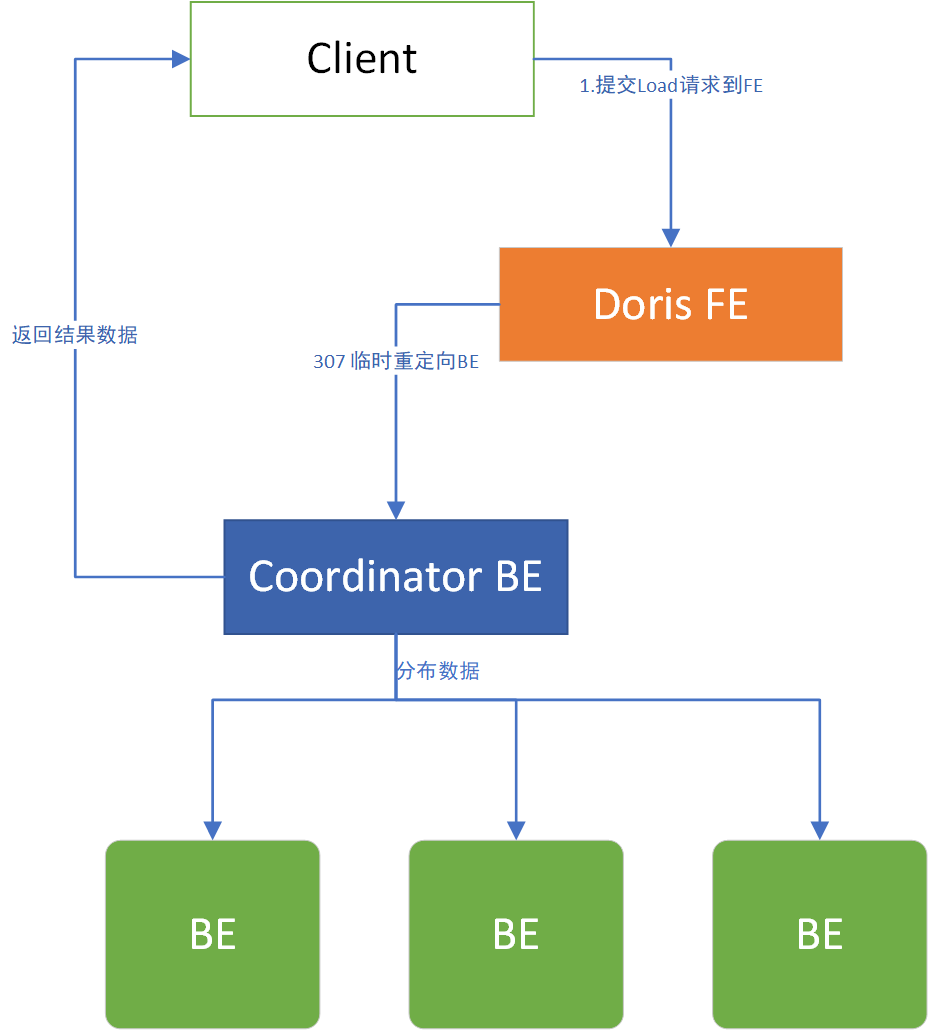
Stream Load请求FE和BE两种方式,连接FE或者直接连接BE方式
Stream load 中,Doris 会选定一个节点作为 Coordinator 节点。该节点负责接数据并分发数据到其他数据节点。
用户通过 HTTP 协议提交导入命令。如果提交到 FE,则 FE 会通过 HTTP redirect 指令将请求转发给某一个 BE。用户也可以直接提交导入命令给某一指定 BE。
导入的最终结果由 Coordinator BE 返回给用户。
3. 使用方式
Stream load 通过 HTTP 协议提交和传输数据。这里通过 curl 命令和Java程序代码方式展示如何提交导入。
用户也可以通过其他 HTTP client 进行操作。
Stream Load 的 HTTP URL地址:
连接FE : http://fe_host:http_port/api/{db}/{table}/_stream_load
连接BE: http://be_host:http_port/api/{db}/{table}/_stream_load
这里FE的http端口默认:8030,BE的HTTP端口:8040
{db}:是表示你要导入数据的数据库名称
{table}:表示你要导入数据的数据表名称
Stream Load HTTP请求方法:PUT
Stream Load是一个同步的数据导入方式,一旦任务开始,无法取消导入任务
3.1 用户认证参数
-
user/passwd
Stream load 由于创建导入的协议使用的是 HTTP 协议,通过 Basic access authentication 进行签名。Doris 系统会根据签名验证用户身份和导入权限。
3.2 导入任务参数说明
Stream load 由于使用的是 HTTP 协议,所以所有导入任务有关的参数均设置在 Header 中。下面主要介绍了 Stream load 导入任务参数的部分参数意义。
-
label
导入任务的标识。每个导入任务,都有一个在单 database 内部唯一的 label。label 是用户在导入命令中自定义的名称。通过这个 label,用户可以查看对应导入任务的执行情况。
label 的另一个作用,是防止用户重复导入相同的数据。强烈推荐用户同一批次数据使用相同的 label。这样同一批次数据的重复请求只会被接受一次,保证了 At-Most-Once
当 label 对应的导入作业状态为 CANCELLED 时,该 label 可以再次被使用。
-
column_separator
用于指定导入文件中的列分隔符,默认为\t。如果是不可见字符,则需要加\x作为前缀,使用十六进制来表示分隔符。
如hive文件的分隔符\x01,需要指定为-H “column_separator:\x01”。
可以使用多个字符的组合作为列分隔符。
-
line_delimiter
用于指定导入文件中的换行符,默认为\n。
可以使用做多个字符的组合作为换行符。
-
max_filter_ratio
导入任务的最大容忍率,默认为0容忍,取值范围是0~1。当导入的错误率超过该值,则导入失败。
如果用户希望忽略错误的行,可以通过设置这个参数大于 0,来保证导入可以成功。
计算公式为:
(dpp.abnorm.ALL / (dpp.abnorm.ALL + dpp.norm.ALL ) ) > max_filter_ratiodpp.abnorm.ALL表示数据质量不合格的行数。如类型不匹配,列数不匹配,长度不匹配等等。dpp.norm.ALL指的是导入过程中正确数据的条数。可以通过SHOW LOAD命令查询导入任务的正确数据量。原始文件的行数 =
dpp.abnorm.ALL + dpp.norm.ALL -
where
导入任务指定的过滤条件。Stream load 支持对原始数据指定 where 语句进行过滤。被过滤的数据将不会被导入,也不会参与 filter ratio 的计算,但会被计入
num_rows_unselected。 -
partition
待导入表的 Partition 信息,如果待导入数据不属于指定的 Partition 则不会被导入。这些数据将计入
dpp.abnorm.ALL -
columns
待导入数据的函数变换配置,目前 Stream load 支持的函数变换方法包含列的顺序变化以及表达式变换,其中表达式变换的方法与查询语句的一致。
列顺序变换例子:原始数据有三列(src_c1,src_c2,src_c3), 目前doris表也有三列(dst_c1,dst_c2,dst_c3) 如果原始表的src_c1列对应目标表dst_c1列,原始表的src_c2列对应目标表dst_c2列,原始表的src_c3列对应目标表dst_c3列,则写法如下: columns: dst_c1, dst_c2, dst_c3 如果原始表的src_c1列对应目标表dst_c2列,原始表的src_c2列对应目标表dst_c3列,原始表的src_c3列对应目标表dst_c1列,则写法如下: columns: dst_c2, dst_c3, dst_c1 表达式变换例子:原始文件有两列,目标表也有两列(c1,c2)但是原始文件的两列均需要经过函数变换才能对应目标表的两列,则写法如下: columns: tmp_c1, tmp_c2, c1 = year(tmp_c1), c2 = month(tmp_c2) 其中 tmp_*是一个占位符,代表的是原始文件中的两个原始列。 -
exec_mem_limit
导入内存限制。默认为 2GB,单位为字节。
-
strict_mode
Stream load 导入可以开启 strict mode 模式。开启方式为在 HEADER 中声明
strict_mode=true。默认的 strict mode 为关闭。strict mode 模式的意思是:对于导入过程中的列类型转换进行严格过滤。严格过滤的策略如下:
- 对于列类型转换来说,如果 strict mode 为true,则错误的数据将被 filter。这里的错误数据是指:原始数据并不为空值,在参与列类型转换后结果为空值的这一类数据。
- 对于导入的某列由函数变换生成时,strict mode 对其不产生影响。
- 对于导入的某列类型包含范围限制的,如果原始数据能正常通过类型转换,但无法通过范围限制的,strict mode 对其也不产生影响。例如:如果类型是 decimal(1,0), 原始数据为 10,则属于可以通过类型转换但不在列声明的范围内。这种数据 strict 对其不产生影响。
-
merge_type 数据的合并类型,一共支持三种类型APPEND、DELETE、MERGE 其中,APPEND是默认值,表示这批数据全部需要追加到现有数据中,DELETE 表示删除与这批数据key相同的所有行,MERGE 语义 需要与delete 条件联合使用,表示满足delete 条件的数据按照DELETE 语义处理其余的按照APPEND 语义处理
3.3 返回结果
由于 Stream load 是一种同步的导入方式,所以导入的结果会通过创建导入的返回值直接返回给用户。
示例:
{
"TxnId": 1003,
"Label": "b6f3bc78-0d2c-45d9-9e4c-faa0a0149bee",
"Status": "Success",
"ExistingJobStatus": "FINISHED", // optional
"Message": "OK",
"NumberTotalRows": 1000000,
"NumberLoadedRows": 1000000,
"NumberFilteredRows": 1,
"NumberUnselectedRows": 0,
"LoadBytes": 40888898,
"LoadTimeMs": 2144,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 2,
"ReadDataTimeMs": 325,
"WriteDataTimeMs": 1933,
"CommitAndPublishTimeMs": 106,
"ErrorURL": "http://192.168.1.1:8042/api/_load_error_log?file=__shard_0/error_log_insert_stmt_db18266d4d9b4ee5-abb00ddd64bdf005_db18266d4d9b4ee5_abb00ddd64bdf005"
}
下面主要解释了 Stream load 导入结果参数:
-
TxnId:导入的事务ID。用户可不感知。
-
Label:导入 Label。由用户指定或系统自动生成。
-
Status:导入完成状态。
“Success”:表示导入成功。
“Publish Timeout”:该状态也表示导入已经完成,只是数据可能会延迟可见,无需重试。
“Label Already Exists”:Label 重复,需更换 Label。
“Fail”:导入失败。
-
ExistingJobStatus:已存在的 Label 对应的导入作业的状态。
这个字段只有在当 Status 为 “Label Already Exists” 是才会显示。用户可以通过这个状态,知晓已存在 Label 对应的导入作业的状态。”RUNNING” 表示作业还在执行,”FINISHED” 表示作业成功。
-
Message:导入错误信息。
-
NumberTotalRows:导入总处理的行数。
-
NumberLoadedRows:成功导入的行数。
-
NumberFilteredRows:数据质量不合格的行数。
-
NumberUnselectedRows:被 where 条件过滤的行数。
-
LoadBytes:导入的字节数。
-
LoadTimeMs:导入完成时间。单位毫秒。
-
BeginTxnTimeMs:向Fe请求开始一个事务所花费的时间,单位毫秒。
-
StreamLoadPutTimeMs:向Fe请求获取导入数据执行计划所花费的时间,单位毫秒。
-
ReadDataTimeMs:读取数据所花费的时间,单位毫秒。
-
WriteDataTimeMs:执行写入数据操作所花费的时间,单位毫秒。
-
CommitAndPublishTimeMs:向Fe请求提交并且发布事务所花费的时间,单位毫秒。
-
ErrorURL:如果有数据质量问题,通过访问这个 URL 查看具体错误行。
3.4 使用示例
3.4.1 CURL示例
下面是命令示例
curl --location-trusted -u user:passwd [-H ""...] -T data.file -XPUT http://fe_host:http_port/api/{db}/{table}/_stream_load
Header 中支持属性见的 ‘导入任务参数’ 说明
格式为: -H "key1:value1"
导入示例:
这个是将test.csv文件导入到test数据库的test_01表中,导入的label名称是test_123,使用的用户:root,密码为空
curl --location-trusted -u root -T test.csv -H "label:test_123" http://abc.com:8030/api/test/test_01/_stream_load
因为Stream Load 是一个同步导入方式,导入成功以后会立马返回结果,返回结果为JSON格式
3.4.2 Java 代码方式
上面CURL方式在实际的生产过程中很少使用,一般用在测试中,下面我们重点介绍基于Java代码方式怎么去使用Stream Load实现数据的导入操作。
这里我们演示两种的导入方式,一种是通过文件,一种是内存中的数据流,两种方式分别演示文本和JSON格式的数据导入,
这个示例是通过连接FE使用Stream Load方式入库,你也可以连接BE
Doris 数据表:
这里我们建立一张简单的商品信息表
CREATE TABLE `doris_test_sink` (
`id` int NULL COMMENT "",
`number` int NULL COMMENT "",
`price` DECIMAL(12,2) NULL COMMENT "",
`skuname` varchar(40) NULL COMMENT "",
`skudesc` varchar(200) NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`id`)
COMMENT "商品信息表"
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_num" = "3",
"in_memory" = "false",
"storage_format" = "V2"
);
文本文件内容,将下面的内容保存到文件中
10001,12,13.3, test1,this is atest
10002,100,15.3,test2,this is atest
10003,102,16.3,test3,this is atest
10004,120,17.3,test4,this is atest
JSON格式的数据:
{
"id":556393582,
"number":"123344",
"price":"23.5",
"skuname":"test",
"skudesc":"zhangfeng_test,test"
}
下面给出示例代码:
import org.apache.commons.codec.binary.Base64;
import org.apache.http.HttpHeaders;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPut;
import org.apache.http.entity.FileEntity;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.DefaultRedirectStrategy;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.File;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.UUID;
/**
* This example mainly demonstrates how to use stream load to import data
* Including file type (CSV) and data in JSON format
*
*/
public class DorisStreamLoader {
// FE IP Address
private final static String HOST = "10.220.146.10";
// FE port
private final static int PORT = 8030;
// db name
private final static String DATABASE = "test_2";
// table name
private final static String TABLE = "doris_test_sink";
//user name
private final static String USER = "root";
//user password
private final static String PASSWD = "";
//The path of the local file to be imported
private final static String LOAD_FILE_NAME = "c:/es/1.csv";
//http path of stream load task submission
private final static String loadUrl = String.format("http://%s:%s/api/%s/%s/_stream_load",
HOST, PORT, DATABASE, TABLE);
//构建HTTP客户端
private final static HttpClientBuilder httpClientBuilder = HttpClients
.custom()
.setRedirectStrategy(new DefaultRedirectStrategy() {
@Override
protected boolean isRedirectable(String method) {
// If the connection target is FE, you need to deal with 307 redirect。
return true;
}
});
/**
* 文件数据导入
* @param file
* @throws Exception
*/
public void load(File file) throws Exception {
try (CloseableHttpClient client = httpClientBuilder.build()) {
HttpPut put = new HttpPut(loadUrl);
put.removeHeaders(HttpHeaders.CONTENT_LENGTH);
put.removeHeaders(HttpHeaders.TRANSFER_ENCODING);
put.setHeader(HttpHeaders.EXPECT, "100-continue");
put.setHeader(HttpHeaders.AUTHORIZATION, basicAuthHeader(USER, PASSWD));
// You can set stream load related properties in the Header, here we set label and column_separator.
put.setHeader("label", UUID.randomUUID().toString());
put.setHeader("column_separator", ",");
// Set up the import file. Here you can also use StringEntity to transfer arbitrary data.
FileEntity entity = new FileEntity(file);
put.setEntity(entity);
try (CloseableHttpResponse response = client.execute(put)) {
String loadResult = "";
if (response.getEntity() != null) {
loadResult = EntityUtils.toString(response.getEntity());
}
final int statusCode = response.getStatusLine().getStatusCode();
if (statusCode != 200) {
throw new IOException(String.format("Stream load failed. status: %s load result: %s", statusCode, loadResult));
}
System.out.println("Get load result: " + loadResult);
}
}
}
/**
* JSON格式的数据导入
* @param jsonData
* @throws Exception
*/
public void loadJson(String jsonData) throws Exception {
try (CloseableHttpClient client = httpClientBuilder.build()) {
HttpPut put = new HttpPut(loadUrl);
put.removeHeaders(HttpHeaders.CONTENT_LENGTH);
put.removeHeaders(HttpHeaders.TRANSFER_ENCODING);
put.setHeader(HttpHeaders.EXPECT, "100-continue");
put.setHeader(HttpHeaders.AUTHORIZATION, basicAuthHeader(USER, PASSWD));
// You can set stream load related properties in the Header, here we set label and column_separator.
put.setHeader("label", UUID.randomUUID().toString());
put.setHeader("column_separator", ",");
put.setHeader("format", "json");
// Set up the import file. Here you can also use StringEntity to transfer arbitrary data.
StringEntity entity = new StringEntity(jsonData);
put.setEntity(entity);
try (CloseableHttpResponse response = client.execute(put)) {
String loadResult = "";
if (response.getEntity() != null) {
loadResult = EntityUtils.toString(response.getEntity());
}
final int statusCode = response.getStatusLine().getStatusCode();
if (statusCode != 200) {
throw new IOException(String.format("Stream load failed. status: %s load result: %s", statusCode, loadResult));
}
System.out.println("Get load result: " + loadResult);
}
}
}
/**
* 封装认证信息
* @param username
* @param password
* @return
*/
private String basicAuthHeader(String username, String password) {
final String tobeEncode = username + ":" + password;
byte[] encoded = Base64.encodeBase64(tobeEncode.getBytes(StandardCharsets.UTF_8));
return "Basic " + new String(encoded);
}
public static void main(String[] args) throws Exception {
DorisStreamLoader loader = new DorisStreamLoader();
//file load
//File file = new File(LOAD_FILE_NAME);
//loader.load(file);
//json load
String jsonData = "{\"id\":556393582,\"number\":\"123344\",\"price\":\"23.5\",\"skuname\":\"test\",\"skudesc\":\"zhangfeng_test,test\"}";
loader.loadJson(jsonData);
}
}
3.4.3 KFD(Kafka + Flink + Doris)
这里我们介绍的是通过Doris提供的Stream load 结合Flink计算引擎怎么实现数据实时快速入库操作。
这里我们演示的是通过Canal采集Mysql 数据库的数据推送到 Kafka ,然后通过Flink 消费Kafka的数据使用Stream Load方式将数据导入到Doris对应的表中
这个方案的好处是,你可以借助于Flink的实时计算能力,在读取到数据之后,对数据进行实时加工处理,并将结果推送到指定的地方,满足实时计算的需求,同时对数据进行ETL操作,将处理后的明细数据存储到Doris的数仓中,满足后续的数据分析需求。
这里我们以 Flink 为例,Spark原理代码差不多,
这里我们演示是以JSON格式的数据。
3.4.3.1 Doris Sink
首先我们实现一个Flink 的 Doris Sink
public class DorisSink extends RichSinkFunction<String> {
private static final Logger log = LoggerFactory.getLogger(DorisSink.class);
private final static List<String> DORIS_SUCCESS_STATUS = new ArrayList<>(Arrays.asList("Success", "Publish Timeout"));
private DorisStreamLoad dorisStreamLoad;
private String columns;
private String jsonFormat;
public DorisSink(DorisStreamLoad dorisStreamLoad, String columns, String jsonFormat) {
this.dorisStreamLoad = dorisStreamLoad;
this.columns = columns;
this.jsonFormat = jsonFormat;
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
}
/**
* 判断StreamLoad是否成功
* @param respContent streamload返回的响应信息(JSON格式)
* @return
*/
public static Boolean checkStreamLoadStatus(RespContent respContent) {
if (DORIS_SUCCESS_STATUS.contains(respContent.getStatus())
&& respContent.getNumberTotalRows() == respContent.getNumberLoadedRows()) {
return true;
} else {
return false;
}
}
@Override
public void invoke(String value, Context context) throws Exception {
DorisStreamLoad.LoadResponse loadResponse = dorisStreamLoad.loadBatch(value, columns, jsonFormat);
if (loadResponse != null && loadResponse.status == 200) {
RespContent respContent = JSON.parseObject(loadResponse.respContent, RespContent.class);
if (!checkStreamLoadStatus(respContent)) {
log.error("Stream Load fail{}:", loadResponse);
}
} else {
log.error("Stream Load Request failed:{}", loadResponse);
}
}
}
3.4.3.2 Doris Stream Load 导入工具类
public class DorisStreamLoad implements Serializable {
private static final Logger log = LoggerFactory.getLogger(DorisStreamLoad.class);
//连接地址,这里使用的是连接FE
private static String loadUrlPattern = "http://%s/api/%s/%s/_stream_load?";
//fe ip地址
private String hostPort;
//数据库
private String db;
//要导入的数据表名
private String tbl;
//用户名
private String user;
//密码
private String passwd;
private String loadUrlStr;
private String authEncoding;
public DorisStreamLoad(String hostPort, String db, String tbl, String user, String passwd) {
this.hostPort = hostPort;
this.db = db;
this.tbl = tbl;
this.user = user;
this.passwd = passwd;
this.loadUrlStr = String.format(loadUrlPattern, hostPort, db, tbl);
this.authEncoding = Base64.getEncoder().encodeToString(String.format("%s:%s", user, passwd).getBytes(StandardCharsets.UTF_8));
}
//获取http连接信息
private HttpURLConnection getConnection(String urlStr, String label, String columns, String jsonformat) throws IOException {
URL url = new URL(urlStr);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setInstanceFollowRedirects(false);
conn.setRequestMethod("PUT");
conn.setRequestProperty("Authorization", "Basic " + authEncoding);
conn.addRequestProperty("Expect", "100-continue");
conn.addRequestProperty("Content-Type", "text/plain; charset=UTF-8");
conn.addRequestProperty("label", label);
conn.addRequestProperty("max_filter_ratio", "0");
conn.addRequestProperty("strict_mode", "true");
conn.addRequestProperty("columns", columns);
conn.addRequestProperty("format", "json");
conn.addRequestProperty("jsonpaths", jsonformat);
conn.addRequestProperty("strip_outer_array", "true");
conn.setDoOutput(true);
conn.setDoInput(true);
return conn;
}
public static class LoadResponse {
public int status;
public String respMsg;
public String respContent;
public LoadResponse(int status, String respMsg, String respContent) {
this.status = status;
this.respMsg = respMsg;
this.respContent = respContent;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("status: ").append(status);
sb.append(", resp msg: ").append(respMsg);
sb.append(", resp content: ").append(respContent);
return sb.toString();
}
}
//执行数据导入
public LoadResponse loadBatch(String data, String columns, String jsonformat) {
Calendar calendar = Calendar.getInstance();
//导入的lable,全局唯一
String label = String.format("flink_import_%s%02d%02d_%02d%02d%02d_%s",
calendar.get(Calendar.YEAR), calendar.get(Calendar.MONTH) + 1, calendar.get(Calendar.DAY_OF_MONTH),
calendar.get(Calendar.HOUR_OF_DAY), calendar.get(Calendar.MINUTE), calendar.get(Calendar.SECOND),
UUID.randomUUID().toString().replaceAll("-", ""));
HttpURLConnection feConn = null;
HttpURLConnection beConn = null;
try {
// build request and send to fe
feConn = getConnection(loadUrlStr, label, columns, jsonformat);
int status = feConn.getResponseCode();
// fe send back http response code TEMPORARY_REDIRECT 307 and new be location
if (status != 307) {
throw new Exception("status is not TEMPORARY_REDIRECT 307, status: " + status);
}
String location = feConn.getHeaderField("Location");
if (location == null) {
throw new Exception("redirect location is null");
}
// build request and send to new be location
beConn = getConnection(location, label, columns, jsonformat);
// send data to be
BufferedOutputStream bos = new BufferedOutputStream(beConn.getOutputStream());
bos.write(data.getBytes());
bos.close();
// get respond
status = beConn.getResponseCode();
String respMsg = beConn.getResponseMessage();
InputStream stream = (InputStream) beConn.getContent();
BufferedReader br = new BufferedReader(new InputStreamReader(stream));
StringBuilder response = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
response.append(line);
}
return new LoadResponse(status, respMsg, response.toString());
} catch (Exception e) {
e.printStackTrace();
String err = "failed to load audit via AuditLoader plugin with label: " + label;
log.warn(err, e);
return new LoadResponse(-1, e.getMessage(), err);
} finally {
if (feConn != null) {
feConn.disconnect();
}
if (beConn != null) {
beConn.disconnect();
}
}
}
}
3.4.3.3 Flink Job
public class FlinkKafka2Doris {
//kafka address
private static final String bootstrapServer = "xxx:9092,xxx:9092,xxx:9092";
//kafka groupName
private static final String groupName = "test_flink_doris_group";
//kafka topicName
private static final String topicName = "test_flink_doris";
//doris ip port
private static final String hostPort = "xxx:8030";
//doris dbName
private static final String dbName = "db1";
//doris tbName
private static final String tbName = "tb1";
//doris userName
private static final String userName = "root";
//doris password
private static final String password = "";
//doris columns
private static final String columns = "name,age,price,sale";
//json format
private static final String jsonFormat = "[\"$.name\",\"$.age\",\"$.price\",\"$.sale\"]";
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", bootstrapServer);
props.put("group.id", groupName);
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");
props.put("max.poll.records", "10000");
StreamExecutionEnvironment blinkStreamEnv = StreamExecutionEnvironment.getExecutionEnvironment();
blinkStreamEnv.enableCheckpointing(10000); blinkStreamEnv.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<>(topicName,
new SimpleStringSchema(),
props);
DataStreamSource<String> dataStreamSource = blinkStreamEnv.addSource(flinkKafkaConsumer);
DorisStreamLoad dorisStreamLoad = new DorisStreamLoad(hostPort, dbName, tbName, userName, password);
dataStreamSource.addSink(new DorisSink(dorisStreamLoad,columns,jsonFormat));
blinkStreamEnv.execute("flink kafka to doris");
}
}
这个地方演示的是单表,如果是你通过Canal监听的多个表的数据,这里你需要根据表名进行区分,并和你mysql表和doris里的表建好对应关系,解析相应的数据即可,配合元数据管理使用效果更佳,我后面我讲解基于Doris怎么构建元数据管理系统,及元数据管理和其他模块的整合使用
最后将程序打成jar包提交到Flink集群运行即可。
3.5 最佳实践
3.5.1 实时性高,数据量大
对于实时性要求较高,数据量比较大的情况,也可以使用Stream load,这时候建议方式是借助以Doris意外的处理引擎,例如:Spark/Flink集群,前端使用Kafka或者Pulsar来完成数据高吞吐,然后借助以Spark/Flink的分布式集群计算处理能力,对Kafka的数据进行消费,然后通过Stream Load的方式进行入库操作。
Stream Load 使用建议:
- 每个批次最大入库记录数,或者每个多少秒进行一次入库,如果你的实时数据量比较小,或者你的数据比较大,这两条件哪个先到执行哪个
- 这里连接是FE,你可以通过FE的 rest api(
/api/show_proc?path=/backends)接口拿到所有的BE节点,直接连接BE进行入库,这里通过Rest API或者BE节点列表,需要admin权限的用户才可以 - 为了避免你连接这个BE或者FE的时候,正好这个节点挂了,你可以进行重试其他FE或者BE
- 为了避免单个节点压力,你可以进行轮训BE节点,不要每次都连接同一个BE节点
- 设置最大重试次数,如果超过这个次数,可以将导入失败的数据推送到Kafka队列,以方便后续人工手动处理
3.5.2 导入数据量建议
由于 Stream load 的原理是由 BE 发起的导入并分发数据,建议的导入数据量在 1G 到 10G 之间。由于默认的最大 Stream load 导入数据量为 10G,所以如果要导入超过 10G 的文件需要修改 BE 的配置 streaming_load_max_mb
比如:待导入文件大小为15G
修改 BE 配置 streaming_load_max_mb 为 16000 即可。
Stream load 的默认超时为 300秒,按照 Doris 目前最大的导入限速来看,约超过 3G 的文件就需要修改导入任务默认超时时间了。
导入任务超时时间 = 导入数据量 / 10M/s (具体的平均导入速度需要用户根据自己的集群情况计算)
例如:导入一个 10G 的文件
timeout = 1000s 等于 10G / 10M/s
3.5.3 导入关键参数说明
FE 配置
-
stream_load_default_timeout_second
导入任务的超时时间(以秒为单位),导入任务在设定的 timeout 时间内未完成则会被系统取消,变成 CANCELLED。
默认的 timeout 时间为 600 秒。如果导入的源文件无法在规定时间内完成导入,用户可以在 stream load 请求中设置单独的超时时间。
或者调整 FE 的参数
stream_load_default_timeout_second来设置全局的默认超时时间。
BE 配置
-
streaming_load_max_mb
Stream load 的最大导入大小,默认为 10G,单位是 MB。如果用户的原始文件超过这个值,则需要调整 BE 的参数
streaming_load_max_mb。
4 注意事项
在社区版 0.14.0 及之前的版本及百度发行版0.14.13之前的版本在启用Http V2之后出现connection reset异常,因为Web 容器内置的是tomcat,Tomcat 在 307 (Temporary Redirect) 是有坑的,对这个协议实现是有问题的,所有在使用Stream load 导入大数据量的情况下会出现connect reset异常,这个是因为tomcat在做307跳转之前就开始了数据传输,这样就造成了BE收到的数据请求的时候缺少了认证信息,之后将内置容器改成了Jetty解决了这个问题,如果你遇到这个问题,请升级你的Doris或者禁用Http V2(enable_http_server_v2=false)。
升级以后同时升级你程序的http client 版本到 4.5.13,在你的pom.xml文件中引入下面的依赖
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>




