Apache Doris Sequence介绍及使用方法
Sequence列目前只支持Uniq模型,Uniq模型主要针对需要唯一主键的场景,可以保证主键唯一性约束,但是由于使用REPLACE聚合方式,在同一批次中导入的数据,替换顺序不做保证。替换顺序无法保证则无法确定最终导入到表中的具体数据,存在了不确定性。
为了解决这个问题,Doris支持了sequence列,通过用户在导入时指定sequence列,相同key列下,REPLACE聚合类型的列将按照sequence列的值进行替换,较大值可以替换较小值,反之则无法替换。该方法将顺序的确定交给了用户,由用户控制替换顺序。
1. 原理
Doris为了满足顺序更新的问题,通过增加一个隐藏列__DORIS_SEQUENCE_COL__实现,该列的类型由用户在建表时指定,在导入时确定该列具体值,并依据该值对REPLACE列进行替换。
2. 建表
Sequence目前只能在Unique Key模型上。
创建Uniq表时,将按照用户指定类型自动添加一个隐藏列__DORIS_SEQUENCE_COL__,这里不需要显示的指定列只需要在PROPERTIES 里加一个属性 function_column.sequence_type
示例:
CREATE TABLE user_log_1 (
user_id VARCHAR(20),
item_id VARCHAR(30),
category_id VARCHAR(30),
behavior VARCHAR(30),
ts datetime
) ENGINE=OLAP
UNIQUE KEY(`user_id`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_num" = "1",
"function_column.sequence_type" = 'Date',
"in_memory" = "false",
"storage_format" = "V2"
);
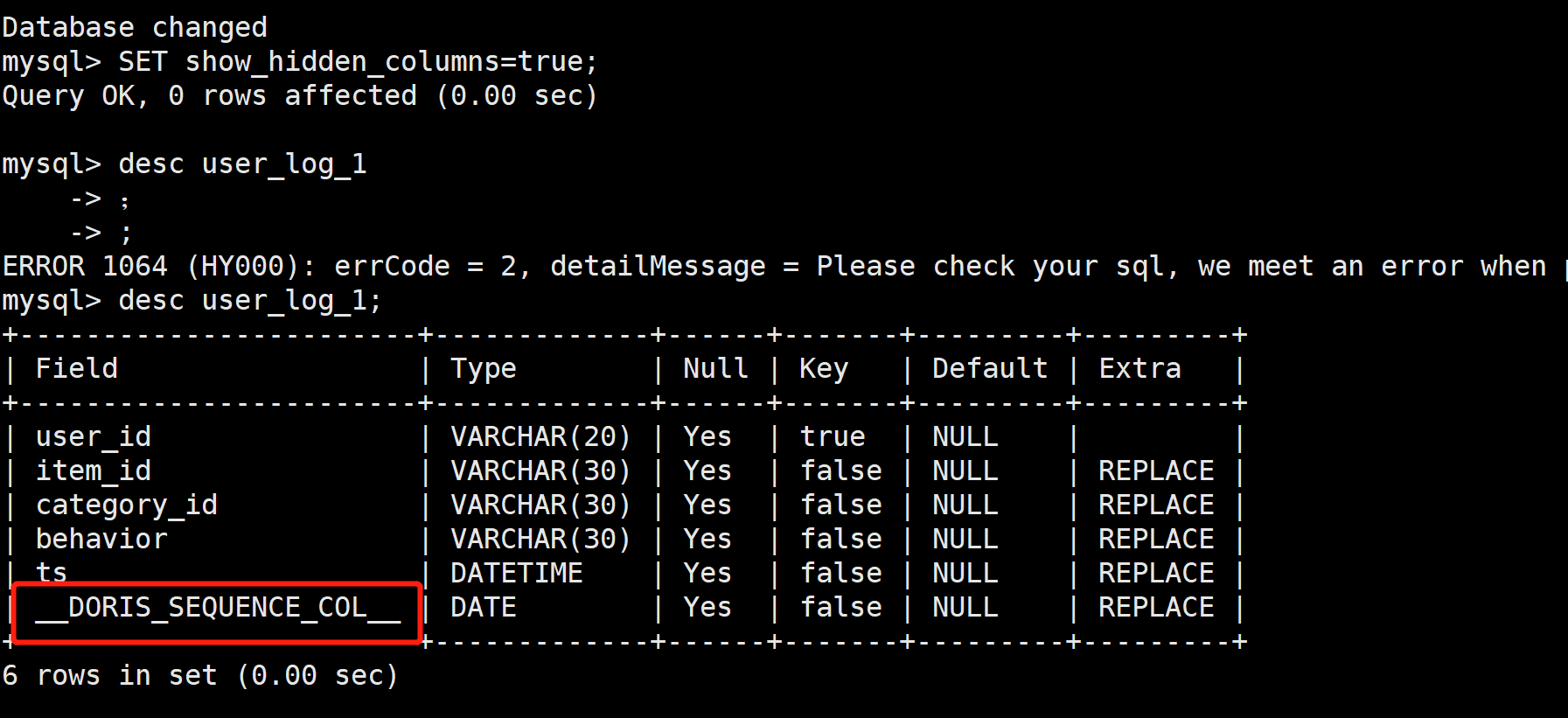
使用下面的命令就可以看到隐藏的列:
SET show_hidden_columns=true;
desc user_log_1
2.1 怎么启用sequence column支持
在新建表时如果设置了function_column.sequence_type ,则新建表将支持sequence column。 对于一个不支持sequence column的表,如果想要使用该功能,可以使用如下语句: ALTER TABLE example_db.my_table ENABLE FEATURE "SEQUENCE_LOAD" WITH PROPERTIES ("function_column.sequence_type" = "Date") 来启用。 如果确定一个表是否支持sequence column,可以通过设置一个session variable来显示隐藏列 SET show_hidden_columns=true ,之后使用desc tablename,如果输出中有__DORIS_SEQUENCE_COL__ 列则支持,如果没有则不支持
3.导入及读取
3.1 导入
导入时,fe在解析的过程中将隐藏列的值设置成 order by 表达式的值(broker load和routine load),或者function_column.sequence_col表达式的值(stream load), value列将按照该值进行替换。隐藏列__DORIS_SEQUENCE_COL__的值既可以设置为数据源中一列,也可以是表结构中的一列。
3.1.1 Stream Load
stream load 的写法是在header中的function_column.sequence_col字段添加隐藏列对应的source_sequence的映射, 示例
curl --location-trusted -u root -H "columns: user_id,item_id,category_id,behavior,ts" -H "function_column.sequence_col: ts" -T testData http://host:port/api/test_2/user_log_1/_stream_load
这里给出的示例是curl的,程序的方式一样,请参照Stream load的部分
3.1.2 Broker Load
在ORDER BY 处设置隐藏列映射的source_sequence字段
LOAD LABEL db1.label1
(
DATA INFILE("hdfs://host:port/user/data/*/test.txt")
INTO TABLE `user_log_1`
COLUMNS TERMINATED BY ","
(user_id,item_id,category_id,behavior,ts)
ORDER BY ts
)
WITH BROKER 'broker'
(
"username"="user",
"password"="pass"
)
PROPERTIES
(
"timeout" = "3600"
);
3.1.3 Routine Load
CREATE ROUTINE LOAD test_2.test1 ON user_log_1
[WITH MERGE|APPEND|DELETE]
COLUMNS(user_id,item_id,category_id,behavior,ts),
[ORDER BY ts]
PROPERTIES
(
"desired_concurrent_number"="3",
"max_batch_interval" = "20",
"max_batch_rows" = "300000",
"max_batch_size" = "209715200",
"strict_mode" = "false"
)
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092",
"kafka_topic" = "my_topic",
"kafka_partitions" = "0,1,2,3",
"kafka_offsets" = "101,0,0,200"
);
3.2 读取
请求包含value列时需要需要额外读取__DORIS_SEQUENCE_COL__列,该列用于在相同key列下,REPLACE聚合函数替换顺序的依据,较大值可以替换较小值,反之则不能替换
4.使用示例
我们继续以上面创建的表为例,通过Stream Load 方式来演示
1,112321,10023,pv,2021-09-27 10:40:34
1,112326,10023,pv,2021-09-27 10:41:34
1,112325,10023,pv,2021-09-27 10:42:34
1,112324,10023,pv,2021-09-27 10:43:34
1,112323,10023,pv,2021-09-27 10:44:34
1,112327,10023,pv,2021-09-27 10:47:34
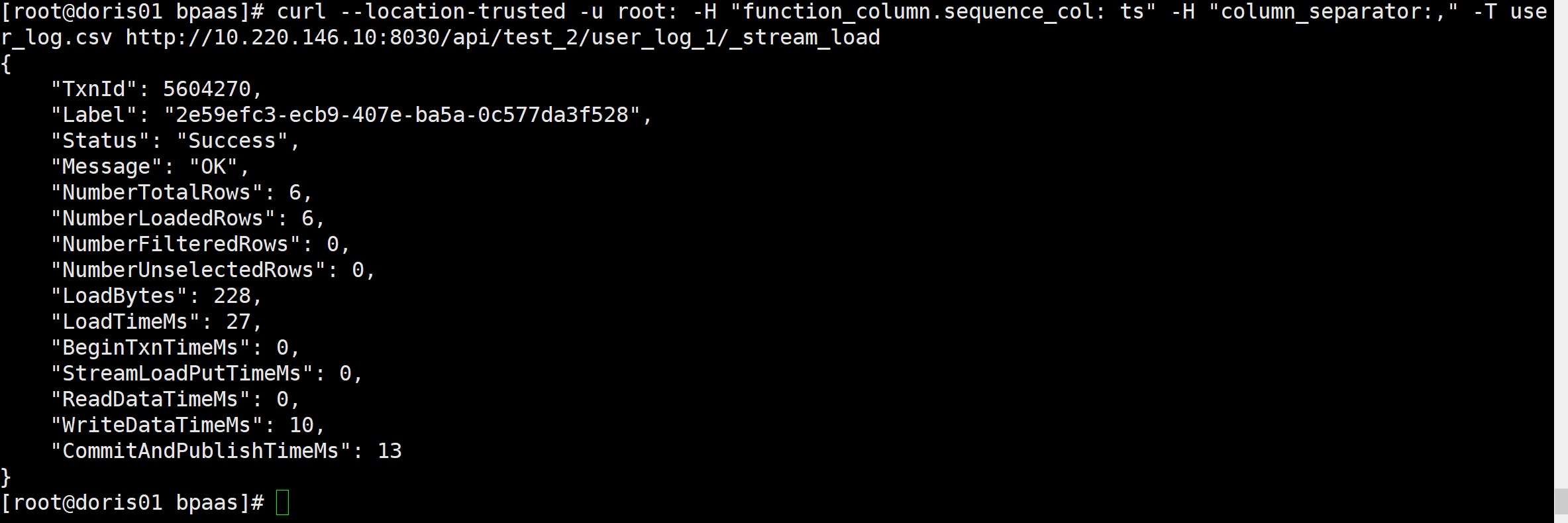
将上面的数据保存成文本文件,然后执行下面命令:
curl --location-trusted -u root: -H "function_column.sequence_col: ts" -H "column_separator:," -T user_log.csv http://10.220.146.10:8030/api/test_2/user_log_1/_stream_load
去查看数据,这个应该只有一条数据,最新时间的那条数据,验证结果如下,是正常的
4.1 替换数据的保证
我们接着导入下面数据
这里的ts字段时间都是小于doris数据表里的那个时间的
1,112321,10023,pv,2021-09-27 10:40:34
1,112326,10023,pv,2021-09-27 10:41:34
1,112325,10023,pv,2021-09-27 10:42:34
1,112324,10023,pv,2021-09-27 10:43:34
1,112323,10023,pv,2021-09-27 10:44:34
我们执行导入
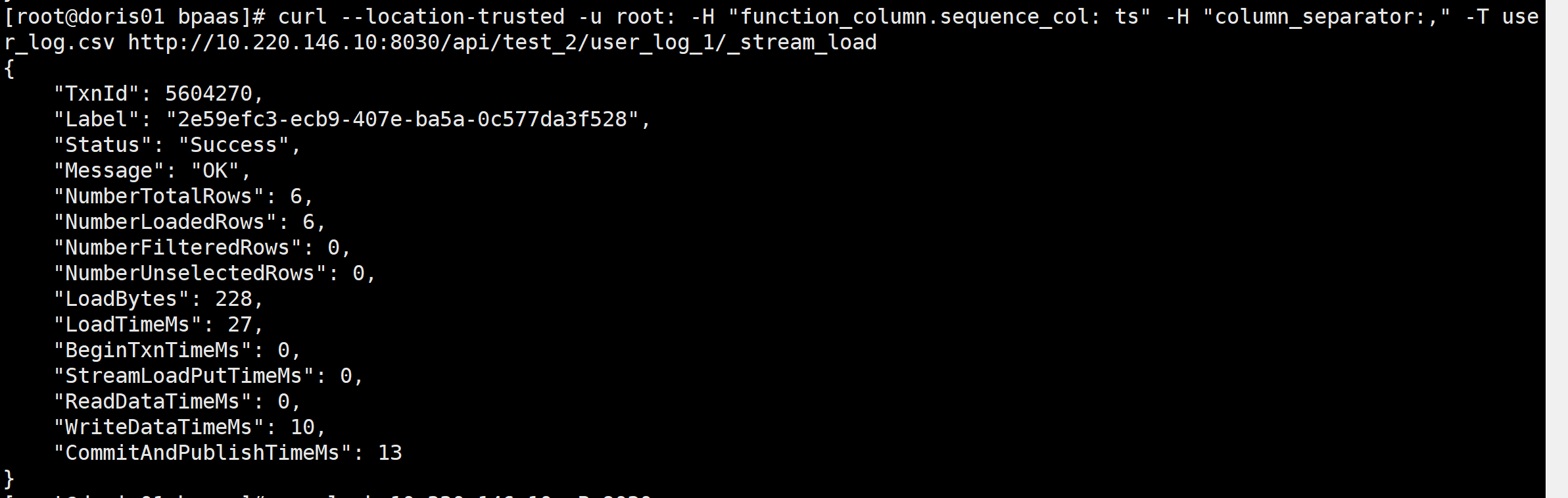
查看结果
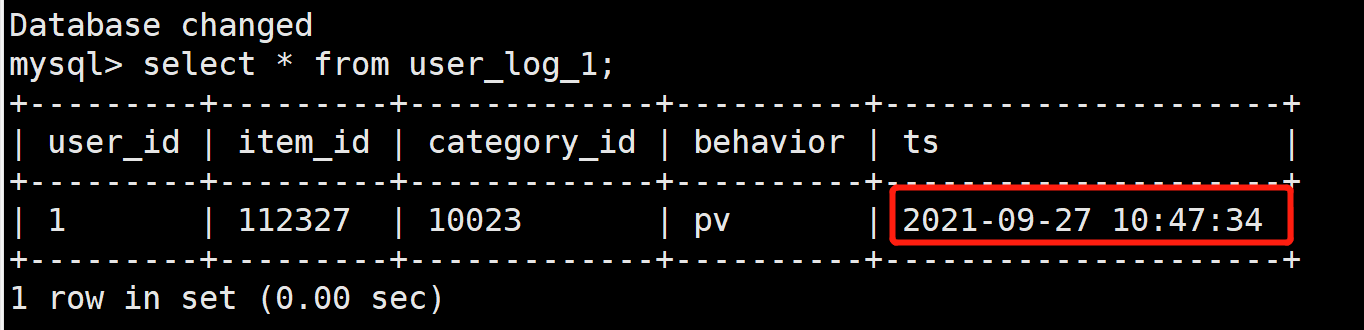
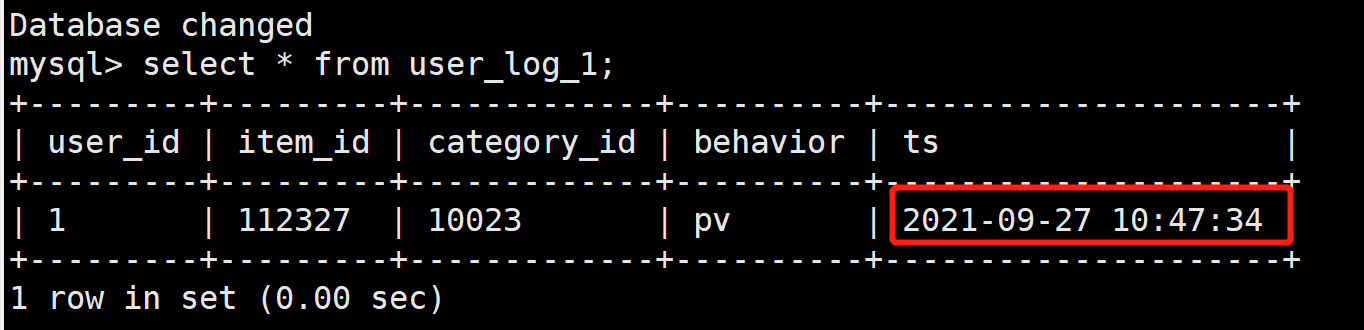
发现由于新导入的数据的sequence column都小于表中已有的值,无法替换。我们重新换一条数据,大于表中已有值的
1,100034,10043,pv,2021-09-28 11:50:34
查看结果,发现数据修改了