
Flink Doris Connector设计方案
从Doris角度看,将其数据引入Flink,可以使用Flink一系列丰富的生态产品,拓宽了产品的想象力,也使得Doris和其他数据源的联合查询成为可能
从我们业务架构出发和业务需求,我们选择了Flink作为我们架构的一部分,用于数据的ETL及实时计算框架,社区目前支持Spark doris connector,因此我们参照Spark doris connector 设计开发了Flink doris Connector。
1.技术选型
一开始我们选型的时候,也是和Spark Doris Connector 一样,开始考虑的是JDBC的方式,但是这种方式就像Spark doris connector那篇文章中说的,有优点,但是缺点更明显。后来我们阅读及测试了Spark的代码,决定站在巨人的肩上来实现
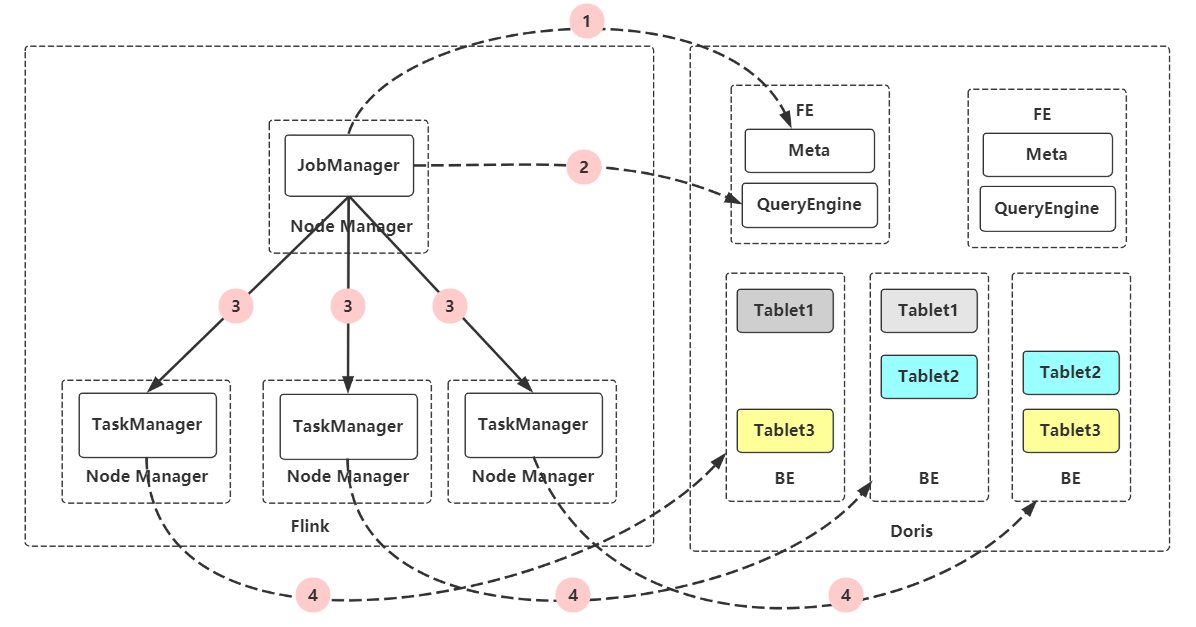
于是我们开发了针对Doris的新的Datasource,Flink-Doris-Connector。这种方案下,Doris可以暴露Doris数据分布给Flink。Flink的Driver访问Doris的FE获取Doris表的Schema和底层数据分布。之后,依据此数据分布,合理分配数据查询任务给Executors。最后,Flink的Executors分别访问不同的BE进行查询。大大提升了查询的效率
2.使用方法
在Doris的代码库的 extension/flink-doris-connector/ 目录下编译生成doris-flink-1.0.0-SNAPSHOT.jar,将这个jar包加入flink的ClassPath中,即可使用Flink-on-Doris功能了
2.1 SQL方式
支持功能:
- 支持通过Flink SQL方式读取Doris数仓里表的数据到Flink里进行计算
- 支持通过Flink SQL将数据insert 到数仓对应的表中,后端实现是通过Stream Load直接和BE进行通讯完成数据插入操作
- 可以通过Flink关联非doris的外部数据源表进行关联分析
示例:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
final StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
tEnv.executeSql(
"CREATE TABLE test_aggregation01 (" +
"user_id STRING," +
"user_city STRING," +
"age INT," +
"last_visit_date STRING" +
") " +
"WITH (\n" +
" 'connector' = 'doris',\n" +
" 'fenodes' = 'doris01:8030',\n" +
" 'table.identifier' = 'demo.test_aggregation',\n" +
" 'username' = 'root',\n" +
" 'password' = ''\n" +
")");
tEnv.executeSql(
"CREATE TABLE test_aggregation02 (" +
"user_id STRING," +
"user_city STRING," +
"age INT," +
"last_visit_date STRING" +
") " +
"WITH (\n" +
" 'connector' = 'doris',\n" +
" 'fenodes' = 'doris01:8030',\n" +
" 'table.identifier' = 'demo.test_aggregation_01',\n" +
" 'username' = 'root',\n" +
" 'password' = ''\n" +
")");
tEnv.executeSql("INSERT INTO test_aggregation02 select * from test_aggregation01");
tEnv.executeSql("select count(1) from test_aggregation01");
2.2 DataStream方式
DorisOptions.Builder options = DorisOptions.builder()
.setFenodes("$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT")
.setUsername("$YOUR_DORIS_USERNAME")
.setPassword("$YOUR_DORIS_PASSWORD")
.setTableIdentifier("$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME");
env.addSource(new DorisSourceFunction<>(options.build(),new SimpleListDeserializationSchema())).print();
3.适用场景
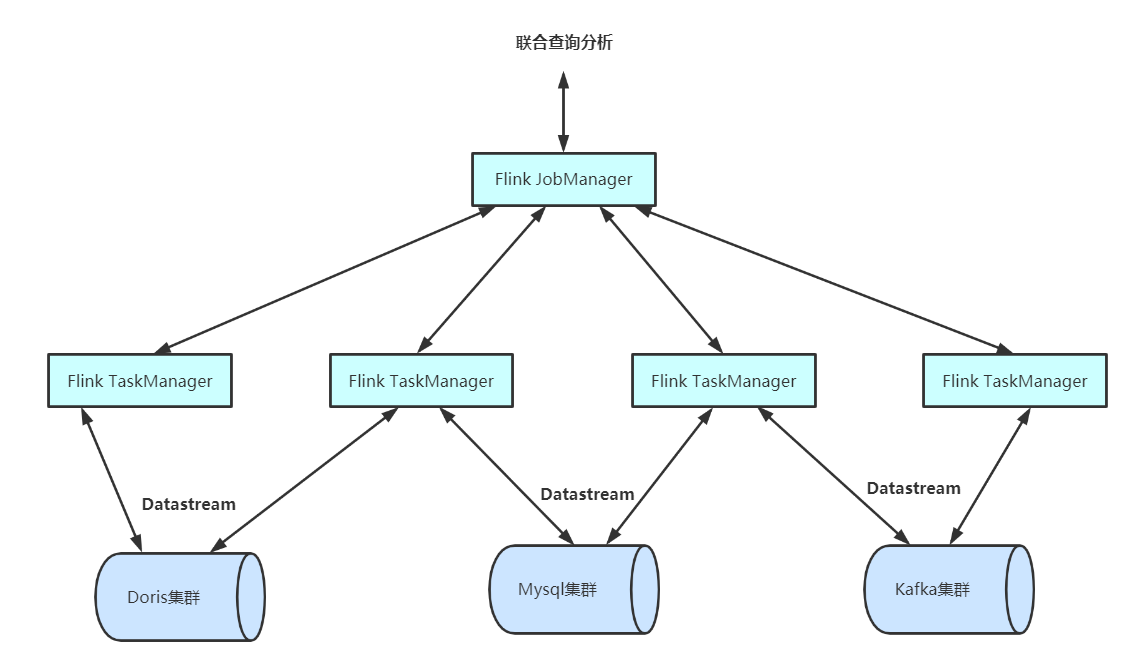
3.1 使用Flink对Doris中的数据和其他数据源进行联合分析
很多业务部门会将自己的数据放在不同的存储系统上,比如一些在线分析、报表的数据放在Doris中,一些结构化检索数据放在Elasticsearch中、一些需要事物的数据放在MySQL中,等等。业务往往需要跨多个存储源进行分析,通过Flink Doris Connector打通Flink和Doris后,业务可以直接使用Flink,将Doris中的数据与多个外部数据源做联合查询计算。
3.2 实时数据接入
Flink Doris Connector之前:针对业务不规则数据,经常需要针对消息做规范处理,空值过滤等写入新的topic,然后再启动Routine load写入Doris。

Flink Doris Connector之后:flink读取kafka,直接写入doris。

4.技术实现
4.1架构图
4.2 Doris对外提供更多能力
4.2.1 Doris FE
对外开放了获取内部表的元数据信息、单表查询规划和部分统计信息的接口。
所有的Rest API接口都需要进行HttpBasic认证,用户名和密码是登录数据库的用户名和密码,需要注意权限的正确分配。
// 获取表schema元信息
GET api/{database}/{table}/_schema
// 获取对单表的查询规划模版
POST api/{database}/{table}/_query_plan
{
"sql": "select k1, k2 from {database}.{table}"
}
// 获取表大小
GET api/{database}/{table}/_count
4.2.2 Doris BE
通过Thrift协议,直接对外提供数据的过滤、扫描和裁剪能力。
service TDorisExternalService {
// 初始化查询执行器
TScanOpenResult open_scanner(1: TScanOpenParams params);
// 流式batch获取数据,Apache Arrow数据格式
TScanBatchResult get_next(1: TScanNextBatchParams params);
// 结束扫描
TScanCloseResult close_scanner(1: TScanCloseParams params);
}
Thrift相关结构体定义可参考:
https://github.com/apache/incubator-doris/blob/master/gensrc/thrift/DorisExternalService.thrift
4.3 实现DataStream
继承 org.apache.flink.streaming.api.functions.source.RichSourceFunction ,自定义DorisSourceFunction,初始化时,获取相关表的执行计划,获取对应的分区。
重写run方法,循环从分区中读取数据。
public void run(SourceContext sourceContext){
//循环读取各分区
for(PartitionDefinition partitions : dorisPartitions){
scalaValueReader = new ScalaValueReader(partitions, settings);
while (scalaValueReader.hasNext()){
Object next = scalaValueReader.next();
sourceContext.collect(next);
}
}
}
4.4 实现Flink SQL on Doris
参考了Flink自定义Source&Sink 和 Flink-jdbc-connector,实现了下面的效果,可以实现用Flink SQL直接操作Doris的表,包括读和写。
4.4.1 实现细节
1.实现DynamicTableSourceFactory , DynamicTableSinkFactory 注册 doris connector
2.自定义DynamicTableSource和DynamicTableSink 生成逻辑计划
3.DorisRowDataInputFormat和DorisDynamicOutputFormat获取到逻辑计划后开始执行。

实现中最主要的是基于RichInputFormat和RichOutputFormat 定制的DorisRowDataInputFormat和DorisDynamicOutputFormat。
在DorisRowDataInputFormat中,将获取到的dorisPartitions 在createInputSplits中 切分成多个分片,用于并行计算。
public DorisTableInputSplit[] createInputSplits(int minNumSplits) {
List<DorisTableInputSplit> dorisSplits = new ArrayList<>();
int splitNum = 0;
for (PartitionDefinition partition : dorisPartitions) {
dorisSplits.add(new DorisTableInputSplit(splitNum++,partition));
}
return dorisSplits.toArray(new DorisTableInputSplit[0]);
}
public RowData nextRecord(RowData reuse) {
if (!hasNext) {
//已经读完数据,返回null
return null;
}
List next = (List)scalaValueReader.next();
GenericRowData genericRowData = new GenericRowData(next.size());
for(int i =0;i<next.size();i++){
genericRowData.setField(i, next.get(i));
}
//判断是否还有数据
hasNext = scalaValueReader.hasNext();
return genericRowData;
}
在DorisRowDataOutputFormat中,通过streamload的方式向doris中写数据。streamload程序参考org.apache.doris.plugin.audit.DorisStreamLoader
public void writeRecord(RowData row) throws IOException {
//streamload 默认分隔符 \t
StringJoiner value = new StringJoiner("\t");
GenericRowData rowData = (GenericRowData) row;
for(int i = 0; i < row.getArity(); ++i) {
value.add(rowData.getField(i).toString());
}
//streamload 写数据
DorisStreamLoad.LoadResponse loadResponse = dorisStreamLoad.loadBatch(value.toString());
System.out.println(loadResponse);
}
5.配置参数
5.1 通用配置项
| Key | Default Value | Comment |
|---|---|---|
| fenodes | – | Doris FE http 地址 |
| table.identifier | – | Doris 表名,如:db1.tbl1 |
| username | – | 访问Doris的用户名 |
| password | – | 访问Doris的密码 |
| doris.request.retries | 3 | 向Doris发送请求的重试次数 |
| doris.request.connect.timeout.ms | 30000 | 向Doris发送请求的连接超时时间 |
| doris.request.read.timeout.ms | 30000 | 向Doris发送请求的读取超时时间 |
| doris.request.query.timeout.s | 3600 | 查询doris的超时时间,默认值为1小时,-1表示无超时限制 |
| doris.request.tablet.size | Integer.MAX_VALUE | 一个Partition对应的Doris Tablet个数。 此数值设置越小,则会生成越多的Partition。从而提升Flink侧的并行度,但同时会对Doris造成更大的压力。 |
| doris.batch.size | 1024 | 一次从BE读取数据的最大行数。增大此数值可减少flink与Doris之间建立连接的次数。 从而减轻网络延迟所带来的的额外时间开销。 |
| doris.exec.mem.limit | 2147483648 | 单个查询的内存限制。默认为 2GB,单位为字节 |
| doris.deserialize.arrow.async | false | 是否支持异步转换Arrow格式到flink-doris-connector迭代所需的RowBatch |
| doris.deserialize.queue.size | 64 | 异步转换Arrow格式的内部处理队列,当doris.deserialize.arrow.async为true时生效 |
| doris.read.field | – | 读取Doris表的列名列表,多列之间使用逗号分隔 |
| doris.filter.query | – | 过滤读取数据的表达式,此表达式透传给Doris。Doris使用此表达式完成源端数据过滤。 |
| sink.batch.size | 100 | 单次写BE的最大行数 |
| sink.max-retries | 1 | 写BE失败之后的重试次数 |
| sink.batch.interval | 1s | flush 间隔时间,超过该时间后异步线程将 缓存中数据写入BE。 默认值为1秒,支持时间单位ms、s、min、h和d。设置为0表示关闭定期写入。 |
| sink.properties.* | – | Stream load 的导入参数。例如:’sink.properties.column_separator’ = ‘,’等。 支持JSON格式导入,需要同时开启’sink.properties.format’ = ‘json’和’sink.properties.strip_outer_array’ = ‘true’ |
5.2 Doris 和 Flink 列类型映射关系
| Doris Type | Flink Type |
|---|---|
| NULL_TYPE | NULL |
| BOOLEAN | BOOLEAN |
| TINYINT | TINYINT |
| SMALLINT | SMALLINT |
| INT | INT |
| BIGINT | BIGINT |
| FLOAT | FLOAT |
| DOUBLE | DOUBLE |
| DATE | STRING |
| DATETIME | STRING |
| DECIMAL | DECIMAL |
| CHAR | STRING |
| LARGEINT | STRING |
| VARCHAR | STRING |
| DECIMALV2 | DECIMAL |
| TIME | DOUBLE |
| HLL | Unsupported datatype |




