
Spark Doris Connector设计方案
Spark Doris Connector 是Doris在0.12版本中推出的新功能。用户可以使用该功能,直接通过Spark对Doris中存储的数据进行读写,支持SQL、Dataframe、RDD等方式。
从Doris角度看,将其数据引入Spark,可以使用Spark一系列丰富的生态产品,拓宽了产品的想象力,也使得Doris和其他数据源的联合查询成为可能
1.技术选型
在早期的方案中,我们直接将Doris的JDBC接口提供给Spark。对于JDBC这个Datasource,Spark侧的工作原理为,Spark的Driver通过JDBC协议,访问Doris的FE,以获取对应Doris表的Schema。然后,按照某一字段,将查询分为多个Partition子查询任务,下发给多个Spark的Executors。Executors将所负责的Partition转换成对应的JDBC查询,直接访问Doris的FE接口,获取对应数据。这种方案几乎无需改动代码,但是因为Spark无法感知Doris的数据分布,会导致打到Doris的查询压力非常大。
于是社区开发了针对Doris的新的Datasource,Spark-Doris-Connector。这种方案下,Doris可以暴露Doris数据分布给Spark。Spark的Driver访问Doris的FE获取Doris表的Schema和底层数据分布。之后,依据此数据分布,合理分配数据查询任务给Executors。最后,Spark的Executors分别访问不同的BE进行查询。大大提升了查询的效率。
2.使用方法
在Doris的代码库的 extension/spark-doris-connector/ 目录下编译生成doris-spark-1.0.0-SNAPSHOT.jar,将这个jar包加入Spark的ClassPath中,即可使用Spark-on-Doris功能了
2.1 读取
2.1.1 SQL
CREATE TEMPORARY VIEW spark_doris
USING doris
OPTIONS(
"table.identifier"="$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME",
"fenodes"="$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT",
"user"="$YOUR_DORIS_USERNAME",
"password"="$YOUR_DORIS_PASSWORD"
);
SELECT * FROM spark_doris;
2.1.2 DataFrame
val dorisSparkDF = spark.read.format("doris")
.option("doris.table.identifier", "$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME")
.option("doris.fenodes", "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT")
.option("user", "$YOUR_DORIS_USERNAME")
.option("password", "$YOUR_DORIS_PASSWORD")
.load()
dorisSparkDF.show(5)
2.1.3 RDD
import org.apache.doris.spark._
val dorisSparkRDD = sc.dorisRDD(
tableIdentifier = Some("$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME"),
cfg = Some(Map(
"doris.fenodes" -> "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT",
"doris.request.auth.user" -> "$YOUR_DORIS_USERNAME",
"doris.request.auth.password" -> "$YOUR_DORIS_PASSWORD"
))
)
dorisSparkRDD.collect()
2.2 写入
2.2.1 SQL方式
CREATE TEMPORARY VIEW spark_doris
USING doris
OPTIONS(
"table.identifier"="$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME",
"fenodes"="$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT",
"user"="$YOUR_DORIS_USERNAME",
"password"="$YOUR_DORIS_PASSWORD"
);
INSERT INTO spark_doris VALUES ("VALUE1","VALUE2",...);
# or
INSERT INTO spark_doris SELECT * FROM YOUR_TABLE
2.2.2 DataFrame(batch/stream)方式
## batch sink
val mockDataDF = List(
(3, "440403001005", "21.cn"),
(1, "4404030013005", "22.cn"),
(33, null, "23.cn")
).toDF("id", "mi_code", "mi_name")
mockDataDF.show(5)
mockDataDF.write.format("doris")
.option("doris.table.identifier", "$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME")
.option("doris.fenodes", "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT")
.option("user", "$YOUR_DORIS_USERNAME")
.option("password", "$YOUR_DORIS_PASSWORD")
.save()
## stream sink(StructuredStreaming)
val kafkaSource = spark.readStream
.option("kafka.bootstrap.servers", "$YOUR_KAFKA_SERVERS")
.option("startingOffsets", "latest")
.option("subscribe", "$YOUR_KAFKA_TOPICS")
.format("kafka")
.load()
kafkaSource.selectExpr("CAST(key AS STRING)", "CAST(value as STRING)")
.writeStream
.format("doris")
.option("checkpointLocation", "$YOUR_CHECKPOINT_LOCATION")
.option("doris.table.identifier", "$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME")
.option("doris.fenodes", "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT")
.option("user", "$YOUR_DORIS_USERNAME")
.option("password", "$YOUR_DORIS_PASSWORD")
.start()
.awaitTermination()
2.3 适用场景
2.3.1 处理历史数据变更
在没有Spark Doris Connector前,Doris修改数据的成本很高,但数据的修改和删除需求在真实业务中时常出现。
Spark Doris Connector之前
方案一:之前导入的错误数据不要删除,采用replace的方式,将错误的数据全部倒入一份负值的,从而将value刷成0,再将正确的数据导入进去。
方案二:把错误数据删除,然后再将正确数据insert进来。
上述方案都存在一个问题,即总有一段时间窗口内数据value为0。这对于外部系统来说是不能容忍的。例如广告主需要查看自己的账户信息,如果因数据变更问题而导致账户显示为0,将是难以接受的,很不友好。
Spark Doris Connector方案
有了Spark Doris Connector,处理历史数据变更将会更加便捷

如上图所示,第一行是错误数据,第二行是正确数据。Spark可以链接两条流,一条流使用Spark Doris Connector连接Doris,一条流连接外部的正确数据(例如业务部门生成的Parquet文件)。在Spark中做diff操作,将所有value算出diff值,即图中最后一行的结果。将其导入进Doris即可。这样的好处是可以消除中间的时间窗口,同时也便于平时经常使用Spark的业务方来进行操作,非常友好。
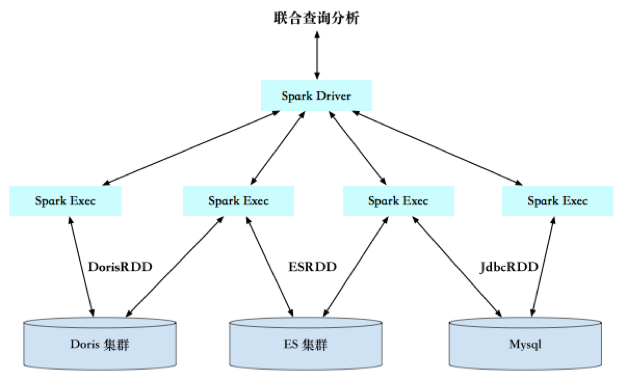
使用Spark对Doris中的数据和其他数据源进行联合分析
很多业务部门会将自己的数据放在不同的存储系统上,比如一些在线分析、报表的数据放在Doris中,一些结构化检索数据放在Elasticsearch中、一些需要事物的数据放在MySQL中,等等。业务往往需要跨多个存储源进行分析,通过Spark Doris Connector打通Spark和Doris后,业务可以直接使用Spark,将Doris中的数据与多个外部数据源做联合查询计算。
2.3.2 数据实时处理写入
目前Spark doris connector 支持通过SQL,DataFrame方式对从数据源中读取数据,通过SQL和DataFrame把数据写入到doris中。同时还可以利用Spark的计算能力对数据进行一些实时计算。
3.相关配置参数
3.1 通用配置
| Key | Default Value | Comment |
|---|---|---|
| doris.fenodes | – | Doris FE http 地址,支持多个地址,使用逗号分隔 |
| doris.table.identifier | – | Doris 表名,如:db1.tbl1 |
| doris.request.retries | 3 | 向Doris发送请求的重试次数 |
| doris.request.connect.timeout.ms | 30000 | 向Doris发送请求的连接超时时间 |
| doris.request.read.timeout.ms | 30000 | 向Doris发送请求的读取超时时间 |
| doris.request.query.timeout.s | 3600 | 查询doris的超时时间,默认值为1小时,-1表示无超时限制 |
| doris.request.tablet.size | Integer.MAX_VALUE | 一个RDD Partition对应的Doris Tablet个数。 此数值设置越小,则会生成越多的Partition。从而提升Spark侧的并行度,但同时会对Doris造成更大的压力。 |
| doris.batch.size | 1024 | 一次从BE读取数据的最大行数。增大此数值可减少Spark与Doris之间建立连接的次数。 从而减轻网络延迟所带来的的额外时间开销。 |
| doris.exec.mem.limit | 2147483648 | 单个查询的内存限制。默认为 2GB,单位为字节 |
| doris.deserialize.arrow.async | false | 是否支持异步转换Arrow格式到spark-doris-connector迭代所需的RowBatch |
| doris.deserialize.queue.size | 64 | 异步转换Arrow格式的内部处理队列,当doris.deserialize.arrow.async为true时生效 |
3.2 SQL 和 Dataframe 专有配置
| Key | Default Value | Comment |
|---|---|---|
| user | – | 访问Doris的用户名 |
| password | – | 访问Doris的密码 |
| doris.filter.query.in.max.count | 100 | 谓词下推中,in表达式value列表元素最大数量。超过此数量,则in表达式条件过滤在Spark侧处理。 |
3.3 RDD 专有配置
| Key | Default Value | Comment |
|---|---|---|
| doris.request.auth.user | – | 访问Doris的用户名 |
| doris.request.auth.password | – | 访问Doris的密码 |
| doris.read.field | – | 读取Doris表的列名列表,多列之间使用逗号分隔 |
| doris.filter.query | – | 过滤读取数据的表达式,此表达式透传给Doris。Doris使用此表达式完成源端数据过滤。 |
3.4 Doris 和 Spark 列类型映射关系
| Doris Type | Spark Type |
|---|---|
| NULL_TYPE | DataTypes.NullType |
| BOOLEAN | DataTypes.BooleanType |
| TINYINT | DataTypes.ByteType |
| SMALLINT | DataTypes.ShortType |
| INT | DataTypes.IntegerType |
| BIGINT | DataTypes.LongType |
| FLOAT | DataTypes.FloatType |
| DOUBLE | DataTypes.DoubleType |
| DATE | DataTypes.StringType1 |
| DATETIME | DataTypes.StringType1 |
| BINARY | DataTypes.BinaryType |
| DECIMAL | DecimalType |
| CHAR | DataTypes.StringType |
| LARGEINT | DataTypes.StringType |
| VARCHAR | DataTypes.StringType |
| DECIMALV2 | DecimalType |
| TIME | DataTypes.DoubleType |
| HLL | Unsupported datatype |
- 注:Connector中,将
DATE和DATETIME映射为String。由于Doris底层存储引擎处理逻辑,直接使用时间类型时,覆盖的时间范围无法满足需求。所以使用String类型直接返回对应的时间可读文本。




